
ここでは,twitterの投稿の分析のためのtweepyの機能に焦点を当てる.
自動でのfollowやtweetの自動投稿などは他の記事を参照してほしい.
使い方は主に,tweepy v3.8.0のofficial documentに載っているGetting startedからAPI Referenceまでを参考にした.
コードはjupyter notebook上での起動を想定する.
tweepyとは?
twitter API を用いるためのmodule. twitter関連のmoduleの中では一番の老舗.
pythonでtwitter APIを使うためのmoduleとしては,”Python Twitter Tools”, “python-twitter”, “twython”, “TwitterAPI”, “TwitterSearch” などが挙げられる.
twitter APIを用いる上で後述の速度制限(Rate limits)に関しては気をつけたい.大規模にtwitterの機能を使おうとすると速度制限は大きな壁になってくるので気をつけたい.
前準備
module のimport
以下のmoduleはimportしておくこととする.
import tweepy import json
twitter apiの取得
tweepyを使うまえのtwitter apiの登録の際には他サイトを参照してほしい.
なお,twitterの登録審査は厳しくなっているようだけれども,個人の利用に関してはそこまで厳しくないような気がする.要求してくる記載内容に関して最低字数を中身を入れて書けば問題なし.僕は,特定の言葉,特定の地域でのtwitter情報を効率良く手に入れたい,という内容を繰り返し書いたら,審査は1~2時間ほどで通ることが出来た.
developerの登録が済むと,以下のGet startedのページに誘導される.Create an appだけやれば,少なくともこの記事の内容を書く分には支障は一切生じなかった.

Create an appの作業を終えて,appの”Detail”を押すとappの詳細が表示される.そのTabの中に “Key and tokens”があるのでkeyとtokenを合わせて4つ手に入れよう.tokenは最初発行されていないのでクリックして発行すること.
その4つを以下のコードに入れるとAPIのインスタンスを作成することが可能だ.
# 認証キーの設定 consumer_key = "API key" consumer_secret = "API secret key" access_token = "Access token" access_token_secret = "Access token secret" # OAuth認証 auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) # APIのインスタンスを生成 api = tweepy.API(auth)
これからの機能の紹介は,ここで作成されたAPIインスタンスを用いて行う.
tweepyのAPI Reference
tweepyでtwitter APIのどんな機能を使えるかはAPI Referenceのページ, ( http://docs.tweepy.org/en/latest/api.html#)に載っているので特定の作業を探したいときはここをみること.また,.pdf版のドキュメントも以下の画像の一番下の部分からダウンロード出来るので好きな方を使える.
*余談だが,API.searchメソッドは,API ReferenceのうちHelp Methodsの中に書かれている...
総論
ここでは,tweepyを使う上で,押さえとくと一つ一つのtweepyの機能が分かりやすくなる機能について述べる.
tweepyの返り値について
基本機能の紹介の前に返り値の処理について述べておく.
tweepyの返り値は主に, “Status” , “User”, “DirectMessage”, “Friendship”, “SearchResults” object,もしくは,json objectが存在する.
json object以外は大抵の場合,”._json” というインスタンスが用意されている.どんなデータが入っているか確認したい場合は”._json”で確認できるということだ.また,”._json”のデータは,各objectのインスタンスとして引き出すことが出来る.
以下のコードで上で述べたことを確認する.
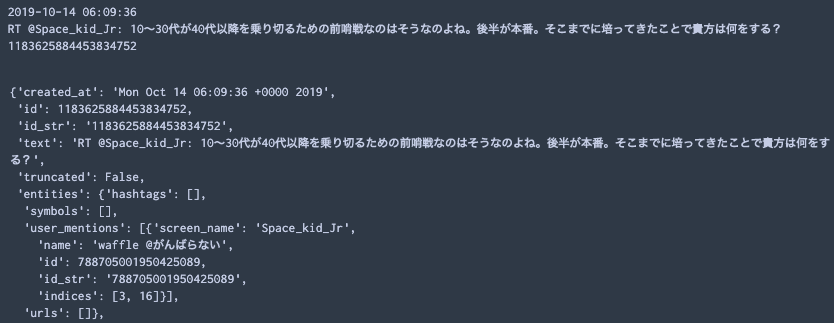
コードは,僕の(accout主)のタイムラインのうち,最新のものの情報を表示する.ここで,”._json”に入っているkeyに対する値と,インスタンスに入っている値が一致していることを確認してほしい.
print(public_tweets[0].created_at) print(public_tweets[0].text) print(public_tweets[0].id) public_tweets[0]._json
また,綺麗にjsonとして格納されているデータを見たい場合は,以下のコードを書けば良い.asciiとして保存されていないデータが多々あるので “ensure_ascii”はFalseにしておく.
もし,jsonファイルのpythonでの取り扱いが分からない場合は,拙著のpandasのデータフレームをjson形式で保存,読み取る方法 を読んでみてほしい.
print(json.dumps(public_tweets[0]._json, indent=4, ensure_ascii=False))

Pagination
Twitter APIにはpageという概念があって,optionで何も選択しなければ1page分の結果がlistとして返ってくる.optionなしの場合の1page分とは,推測だが,twitter official pageのRate Limitsに書かれている1requestsに相当するもの.これは.文字の分量や検索条件の設定の仕方によって変わってくる.
Paginationの概念を理解するためには,次のコードを回してみるとよい.
ある特定のユーザーの全てのタイムラインを30文字目まで表示する.
一列目はページ番号,二列目は一ページの中での要素の順番,三列目にタイムラインの内容を表示する.
*注意! user には,タイムラインの総数が100~1000くらいの人を選ぶこと.数万個のタイムラインを投稿している人を表示しようとすると速度制限に引っかかることが予想される.
*user にはtwitterの名前の表示のうち,最初に”@”が付いたものを入力すること.
# be attention that please choose user which have a few timelines (about 100~1000)
user = "user name"
page = 1
while True:
statuses = api.user_timeline(page=page,id=user)
if statuses:
for i,status in enumerate(statuses):
# process status here
print(page," : ",i," : ",status.text[:30])
else:
# All done
break
page += 1 # next page
ただ,いちいちある人のタイムラインを表示するときにこのようなコードを書くのは煩雑ということでtweepyではCursor objectを提供している.
上と同様に,ある特定のユーザーの全てのタイムラインの内容を表示する.この方法だと,pageの括りがなくなることに注意.また引数は,Cursor objectの中に渡すこと.
*注意! user には,タイムラインの総数が100~1000くらいの人を選ぶこと.数万個のタイムラインを投稿している人を表示しようとすると速度制限に引っかかることが予想される.
user = "user name"
for i, status in enumerate(tweepy.Cursor(api.user_timeline,id=user).items()):
print(i," : ",status.text[:30])
速度制限との兼ね合いでpageごとに処理したい場合は,以下のように書く.また,数字は表示するページの数を指定する. ”.tems()”にも同じような引数を取ることが可能だ.ページが3枚分しか出力されないことに注意.
user = "user name"
for i , page in enumerate(tweepy.Cursor(api.user_timeline,id=user).pages(3)):
# page is a list of statuses
for j , status in enumerate(page):
print(i," : ",j," : ",status.text[:30])
各論
API.user_timeline
特定のユーザーのtimelineを取得する.何も引数を渡さないと自分のtimelineが表示される.
使い方の例として,Donald J. Trumpの直近の投稿を10個表示しよう.
optionを選択しないと,途中で切れてしまうので,tweet_mode=”extended”にすると”.full_text”の中に全文が格納される.ただし,リツイート(冒頭にRTがつくもの)は全文見られないよう.
user = "realDonaldTrump"
for i, status in enumerate(tweepy.Cursor(api.user_timeline,id=user,tweet_mode="extended").items(10)):
print(i," : ",status.full_text)
API.friends , API.followers
API.friendsで特定のユーザー”が”followしている人を,API.followersで特定のユーザー”を”followしている人を表示する.
例として,Barack Obamaのfollowしている人,followされている人をそれぞれ10人ずつ表示する.
user = "BarackObama"
print("Name : @Name")
for status in tweepy.Cursor(api.friends,id=user).items(10):
print("%s : %s "%(status.name,status.screen_name) )
print("-"*100)
for status in tweepy.Cursor(api.followers,id=user).items(10):
print("%s : %s "%(status.name,status.screen_name) )
API.friends_ids, API.followers_ids
あるユーザーに対して,friendsかfollowersのidのみを返す.1 requestで5000件取得することが出来る.これを用いれば,多人数間のfollowしているか,されているかの関係性を調べることが出来る.
後述のAPI.show_friendshipでも関係性の詳細は入手可能だが,1 requestで1組のデータしか得られず,1windowあたり180回しかrequest出来ないため,こっちの方が実は効率的に情報収拾できたりする.
以下のコードは, Obamaさんをfollowしている人のidを2page分取得する.
user_ = "BarackObama"
for i,page in enumerate(tweepy.Cursor(api.followers_ids,id=user_).pages(2)):
for j,userID in enumerate(page):
print("%d : %d : %s "%(i,j,userID) )
API.show_friendship
2つのアカウント間の関係性を表示する.ただ,followしている,されているだけでなく,片方が片方をブロックしているかどうかまで確認することが可能.
ObamaさんとTrumpさんの関係を見ると,どちらもfollowもしてないし,blockもしてなかった.
source_name = "BarackObama" target_name = "realDonaldTrump" friObj = api.show_friendship(source_screen_name=source_name, target_screen_name=target_name) print(friObj[0]._json) print(friObj[1]._json)
API.search
ワードを検索して,その結果を取得する.
例として,場所を指定して,その範囲内でのtweetを見てみる.
geocode には,”経度,緯度,半径km”を入れることで場所の指定が可能.
今回は,札幌市から半径50km以内のtweetのうち,台風でヒットする最新のものから10件を取得する.さらに,投稿日時と,もしユーザー設定の中に場所が登録されていたら,場所も表示するようにした.
for status in tweepy.Cursor(api.search,q="台風",geocode="43.06327,141.331434,50km").items(10):
if "location" in status._json["user"].keys():
print("%s : %sn%sn" %(status.created_at,status.user.location,status.text))
else:
print("%s : nann%sn" %(status.created_at,status.text))
コードを回せば,札幌市で登録している人が多いことから,正しく実装できていることが確認できる.
無料版だと,7日前までのtweetまでしか遡ることができない.また,申請すれば30日前まで遡ってtweetを検索することが可能だ. 詳細はtwitter official siteのSearch Tweets(https://developer.twitter.com/en/docs/tweets/search/overview)を参照のこと.
API.trends_available
これは,twitterがtrendsを取得している場所を記している.
以下のコードを回すと,日本の中でtrendsはどこで収集して処理しているか確認できる.
lis_ = []
for i in api.trends_available():
if i["country"] == "Japan":
lis_.append(i["name"])
print(", ".join(lis_))
Kitakyushu, Saitama, Chiba, Fukuoka, Hamamatsu, Hiroshima, Kawasaki, Kobe, Kumamoto, Nagoya, Niigata, Sagamihara, Sapporo, Sendai, Takamatsu, Tokyo, Yokohama, Okinawa, Osaka, Kyoto, Japan, Okayama
(青森はtrendsすら集めてもらえないことがわかる.)
速度制限(Rate limits)について
速度制限についての概要
twitter APIを使う上で,利用に制限が掛かることは仕方がなく,必ず利用制限の下でプログラムを書く必要がある.利用制限をオーバーして使い続けるとブラックリスト入りして二度とtwitter APIを使えなくなる可能性はある.
そこで,自分がどれだけ利用制限内で利用できているか確認することは重要である.twitter側が利用制限を超過しないような工夫については,にまとめて書かれている.一度目を通しておきたい.
さて,(Rate Limits, https://developer.twitter.com/en/docs/basics/rate-limits)には,リクエストのタイプごとに上限が定められていることが分かる.特にtweetのsearchに関しては,GET saerch/tweets によれば,user単位では180 Requests/windowであることが分かる. このwindowは15分間にという意味だ.
現在の自分の上限とwindowごとにどれくらいまで使っているかは,API.rate_limit_status()によって得ることができる.
print(json.dumps(api.rate_limit_status(),indent=4))
によってファイルの構造を押さえると,searchに関しては,resourcesのsearchにあることが分かる.
以下のコードは,API.searchで紹介したコードで, ページを4個取得する.回すコードの前とあとでカウントが丁度4個減っていることが分かるだろう.
print(api.rate_limit_status()["resources"]["search"])
for i, page in enumerate(tweepy.Cursor(
api.search,q="台風",geocode="43.06327,141.331434,50km"
).pages(4)):
continue
print(api.rate_limit_status()["resources"]["search"])
APIのメソッドごとの速度制限の確認の仕方
今まで紹介してきたAPIのメソッドごとの速度制限の確認の仕方.
一番,下のAPI.rate_limit_statusは,速度制限を確認するメソッドを呼び出す方法自体の呼び出し制限である.
print("API.followers")
print(api.rate_limit_status()["resources"]["followers"]["/followers/list"],"n" +"-"*50)
print("API.friends")
print(api.rate_limit_status()["resources"]["friends"]["/friends/list"],"n" +"-"*50)
print("API.followers_ids")
print(api.rate_limit_status()["resources"]["followers"]["/followers/ids"],"n" +"-"*50)
print("API.friedns_ids")
print(api.rate_limit_status()["resources"]["friends"]["/friends/ids"],"n" +"-"*50)
print("API.show_friendship")
print(api.rate_limit_status()["resources"]["friendships"]["/friendships/show"],"n" +"-"*50)
print("API.search")
print(api.rate_limit_status()["resources"]["search"]["/search/tweets"],"n" +"-"*50)
print("API.rate_limit_status")
print(api.rate_limit_status()["resources"]["application"]["/application/rate_limit_status"],"n" +"-"*50)

Streaming With Tweepy
tweepyはStreaming機能を提供している.検索ワードに対して,リアルタイムの投稿を取得する方法だ.
Streaming APIを使った実装例に興味のある人は以下の記事で書いているので,読んでみてください.
・tweepyのstreaming機能を使った基本的な実装例の紹介
・tweepyでtwitterのアカウント間の関係をグラフ化する
参考文献
[1] Tweepy official document , http://docs.tweepy.org/en/v3.8.0
[2] Accessing the Twitter API with Python , https://stackabuse.com/accessing-the-twitter-api-with-python/
[3] Rate Limits, https://developer.twitter.com/en/docs/basics/rate-limits
[4] Rate Limiting, https://developer.twitter.com/en/docs/basics/rate-limiting
・PythonでTwitter API を利用していろいろ遊んでみる, https://qiita.com/bakira/items/00743d10ec42993f85eb
・Twitter APIをpythonで使うと〇〇ができる。 , https://www.pytry3g.com/entry/python-twitter-api
・ Introduction to tweepy, Twitter for Python, https://www.pythoncentral.io/introduction-to-tweepy-twitter-for-python/
・Tweepyで条件にあうユーザー名を抽出したい , https://teratail.com/questions/142238

コメント
[…] のstreaming API以外のAPI機能の使い方について怪しかったならば,拙著のtwitterのデータ探索に関わるtweepyの基本機能の解説を読んでおくと良い.また,jsonの基本的な操作については,拙著のp […]
[…] 前の記事の内容を使っているので,必要であれば,そちらの記事も確認すること.・twitterのデータ探索に関わるtweepyの基本機能の解説・tweepyのstreaming機能を使った基本的な実装例の紹介 […]