
Google Fomrsで希望を回収してpythonのプログラムで抽選を行いグループ分けを行った. そのプログラムの解説.
コードとデータは,git clone https://github.com/akitoshiblog/blogsite でlottery下にある.
背景
学校の実習で57人を10グループに分けなければいけなくなった.
各グループの定員はバラバラ.
希望調査をして, グループ分けしなければいけない.
→ pythonで抽選プログラムを組み, グループ分けを行いたい!
実際に行った手順
Google Fomrsの設定
・学生番号, 名前, メールアドレス, 第1~4希望を尋ねる.
・その際, グループの名前は選択式にする.
・なりすまし防止のため, 学生番号, 名前, メールアドレスが一致しているかを確認する. 希望を複数回送信した人に関しては, 最新のformを採用する.
注: 僕の場合はgoogle fomrsをgmailアカウントでログインしてから行うようにはしませんでした. しかし, ログインしてからだと, 一つのアカウントに対して回答が一つになるのでdata clearningの部分がいらなくなる.
第一段階
・各グループに第1,2希望が何人いるかを全体に公開
・google formsでもらったメールアドレス当てに, その人が申し込んだ内容の確認と各希望が何%の確率で通るかという情報を載せて送信.
第二段階
・第一段階を受けて希望を変更したい人は追加でgoogle formsを送信してもらう.
・期限が来たら, 抽選して結果を確定.
データ
以下のデータを用いる.
・希望を取る対象の人数は57人.
・タイムスタンプと希望自体は本物.
・名前は 日本人名前自動生成機 より生成したものを使用.
・それに対応した学生番号は1~57を適当につけた.
・メールアドレスは, ランダムな3文字の英数字 + “@gnail.con”とした.
最初の五例は以下の通り
| タイムスタンプ | 学生番号 | 名前 | メールアドレス | 第1希望 | 第2希望 | 第3希望 | 第4希望 |
| 2019/07/04 2:54:43 午後 GMT+9 | 1 | 長門 洋章 | YGa@gnail.con | 7_警察所視察 | 2_小学校視察 | 3_大学視察 | 9_水道局視察 |
| 2019/07/04 3:04:54 午後 GMT+9 | 2 | 長門 真由子 | Hlj@gnail.con | 9_水道局視察 | 2_小学校視察 | 5_ゴミ屋敷視察 | 3_大学視察 |
| 2019/07/04 3:06:45 午後 GMT+9 | 3 | 児玉 渡 | TIn@gnail.con | 8_消防所視察 | 4_官 邸視察 | 3_大学視察 | 2_小学校視察 |
| 2019/07/04 3:23:48 午後 GMT+9 | 4 | 児玉 裕美 | OCW@gnail.con | 9_水道局視察 | 5_ゴミ屋敷視察 | 8_消防所視察 | 10_帰宅 |
グループ名とその定員は以下のようになっている.
| グループ名 | 定員 |
| 1_図書館視察 | 6 |
| 2_小学校視察 | 7 |
| 3_大学視察 | 8 |
| 4_官邸視察 | 5 |
| 5_ゴミ屋敷視察 | 5 |
| 6_病院視察 | 4 |
| 7_警察所視察 | 6 |
| 8_消防所視察 | 2 |
| 9_水道局視察 | 8 |
| 10_帰宅 | 6 |
今回, 希望調査する対象の学生番号と名前が入ったnames.xlsx(いわゆる名簿)も用意する.
最初の五例だけ示すとこんな感じ.
| 学生番号 | 名前 |
| 1 | 長門 洋章 |
| 2 | 長門 真由子 |
| 3 | 児玉 渡 |
| 4 | 児玉 裕美 |
| 5 | 橋爪 義巳 |
データクリーニング
コードはjupyter notebook上で起動することを前提とする.
コード全体で使うmoduleを最初にimport する.
display は jupyter notebook上で綺麗にpandasのデータフレームを表示してくれる. 表示の仕方はCellの最後に置いた時と同じように表示する.
import pandas as pd import numpy as np from datetime import datetime, timedelta import random from scipy.stats import uniform from IPython.display import display
データを読み込む.
pandasのデータフレームのキーをいちいち書くのはめんどくさいので”keys”という変数にキーの名前を保存しておく.
df = pd.read_csv("lottery.csv",header=0)
print(df.shape)
keys = df.keys()
display(df.head())
Google Formsのタイムスタンプをdatetimeの形に読み込む.
dates = df[keys[0]].values
df["datetime"] = np.nan
for i,date in enumerate(dates):
d = df.loc[i,keys[0]]
d_ = datetime.strptime(d[:-9],"%Y/%m/%d %H:%M:%S")
if d[-8:-6] == "午後":
d_ = d_ + timedelta(hours=+12)
df.loc[i,"datetime"] = d_
念の為, 締め切りよりも後に送ってきたgoogle formsがないか確認する.
今回は, 最終締め切りは2019年7月15日の21時にした.
今回のデータでは該当する人は一人もいない.
cond = (df[“datetime”] < deadline)
print(“締切日よりも後に送ってきた人”)
display(df[cond !=1][keys[1:9]])
なりすまし防止のため学生番号が同じ人の中に, 名前とメールアドレスが一致していないものがないか確認する. プログラム上では, 各項目について値の種類が1通りかどうかで確認している. (7行目の部分)
df1 = df[cond]
stuNum = df1[keys[1]].unique()
for stu in stuNum:
flag = False
for k in keys[1:4]:
cond = df1[keys[1]] == stu
if len(df1.loc[cond,k].unique()) != 1:
flag = True
if flag:
display(df1.loc[cond,keys[1:8]])
| 学生番号 | 名前 | メールアドレス | 第1希望 | 第2希望 | 第3希望 | 第4希望 | |
|---|---|---|---|---|---|---|---|
| 4 | 4 | 児玉 裕美 | OCW@gnail.con | 9_水道局視察 | 5_ゴミ屋敷視察 | 8_消防所視察 | 10_帰宅 |
| 39 | 4 | 児玉 裕美 | AkN@gnail.con | 7_警察所視察 | 9_水道局視察 | 10_帰宅 | 8_消防所視察 |
| 69 | 4 | 児玉 裕美 | OCW@gnail.con | 9_水道局視察 | 5_ゴミ屋敷視察 | 10_帰宅 | 4_官邸視察 |
今回は上記のような出力が出てくる. なりすましではなく, メールアドレスの入力ミスが起きていたことが分かる.
最新のformのみを抜き出したデータフレームを作成する. また, 抜き出す前と後での行列の数を確認する.
df1["latest"] = 0
for stu in stuNum:
cond = df1[keys[1]] == stu
dfM = df1.loc[cond]
ind = dfM.index.values
df1.loc[ind[-1],"latest"] = 1
df2 = df1[df1["latest"] == 1]
print("before extracting latest : ",df1.shape," after : ",df2.shape)
names.xlsxに入っている学生番号と名前を用いて, 誰が提出していないのかと, 対象の人が以外が提出していないかを確認する.
# データの読み込み
file = "names.xlsx"
x1 = pd.ExcelFile(file)
Meibo = x1.parse("名簿")
# google formsのデータと名簿のデータから学生番号を抜き出す.
allStuNum = Meibo[keys[1]].values
stuNum = df2[keys[1]].unique()
print("# of people submitting google forms :",len(stuNum))
print("people who still do not submit google forms ")
for num in allStuNum:
if not num in stuNum:
display(Meibo[Meibo[keys[1]] == num])
print("people who are not in the group")
for num in stuNum:
if num not in allStuNum:
display(df2[df2[keys[1]] == num][keys[1:4]])
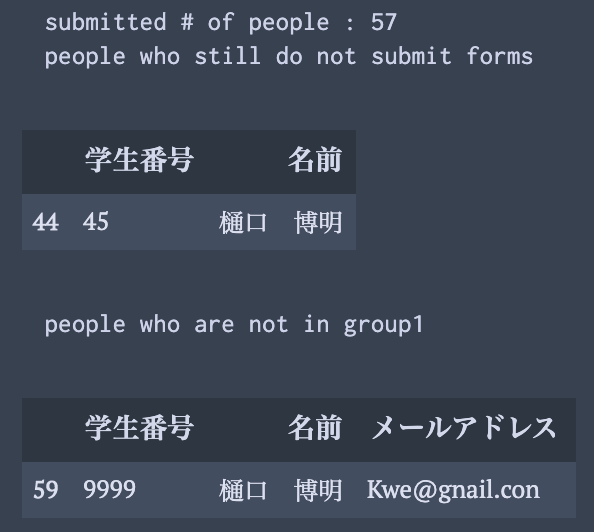
このことから, 樋口が学生番号を誤って入力していることがわかる.
そこで, 児玉のメールアドレスと樋口の学生番号を修正してクリーニングしたデータとして保存する.
df.loc[39,keys[3]] = "OCW@gnail.con"
df.loc[59,keys[1]] = 45
df.to_csv("lottery_cle.csv",header=True,index=False)
再度, データクリーニングの部分のコードをdf.read_csvのpathだけ”lottery_cle.csv”として回し, 異常が出なければ, 以下のコードを回して, そのcsvを抽選に用いる.
df2.to_csv("lottery_latest.csv",header=True,index=False,encoding = "utf-8")
再度書くが, google formsの回答の際に個人のgmailアカウントを用いて回答させれば, このデータクリーニングパートはパスすることができる.
抽選(Lottery) !
事前準備のためのコード
groups = ["1_図書館視察","2_小学校視察","3_大学視察","4_官邸視察","5_ゴミ屋敷視察","6_病院視察","7_警察所視察",
"8_消防所視察","9_水道局視察","10_帰宅"]
fixNumber = [6,7,8,5,5,4,6,2,8,6]
df = pd.read_csv("lottery_latest.csv",header=0)
print(df.shape)
keys = df.keys()
display(df.head())
アルゴリズムはシンプルで第1~4希望それぞれの段階で, まだ決まってない人たちに関して,
・希望者が定員よりも少なければ, 確定
・希望者が定員よりも多ければ, 抽選
を行なっていけばよい.
def lottery(stage):
for i, group in enumerate(groups):
cond = (df_[stage] == group)&(df_["decided"] == "Not yet")
dfM = df_[cond]
if restNum[i] >= dfM.shape[0]:
restNum[i] -= dfM.shape[0]
df_.loc[cond,"decided"] = group
elif restNum[i] < dfM.shape[0]:
ind = list(dfM.index.values)
sel = random.sample(ind,restNum[i])
df_.loc[sel,"decided"] = group
restNum[i] = 0
このlottery関数はstageに”第1希望”を渡すと”第1希望”に関して抽選を行なってくれる.
第1~4希望まで抽選する際は,
restNum = fixNumber.copy()
random.seed(6)
df_ = df.copy()
df_["decided"] = "Not yet"
lottery("第1希望")
lottery("第2希望")
lottery("第3希望")
lottery("第4希望")
df_.sort_values(by="decided").to_excel("decided.xlsx",index=False)
こうすると, 決まらない人がいる可能性は残るが, それらの結果が “decided.xlsx”に保存される.
注意すべき点は, 注意すべき点はリスト型のfixNumberもpandasのデータフレーム型であるdfもコピーをしておかないとそのCellを回すたびに結果が変わってしまう. なのでコピーをしておくことが大事である. また, 関数の中に”df_”があるので名前を変える際はそこも変更すること. (引数として渡すようにするとなお良い.)
各段階で誰が決まっていったか見るために, jupyter notebookに各段階の抽選結果を出力するようにコードを書き加えたものがこちら.
def lottery(stage,s):
for i, group in enumerate(groups):
cond = (df_[stage] == group)&(df_["decided"] == "Not yet")
dfM = df_[cond]
if restNum[i] >= dfM.shape[0]:
restNum[i] -= dfM.shape[0]
df_.loc[cond,"decided"] = group
s += group +"n"
for j in dfM[keys[1:3]].values:
s += "%d : %s n" %(j[0],j[1])
elif restNum[i] < dfM.shape[0]:
ind = list(dfM.index.values)
sel = random.sample(ind,restNum[i])
df_.loc[sel,"decided"] = group
s += group +"n"
for j in dfM.loc[sel,keys[1:3]].values:
s += "%d : %s n" %(j[0],j[1])
restNum[i] = 0
restNum = fixNumber.copy()
random.seed(6)
df_ = df.copy()
df_["decided"] = "Not yet"
s = ""
s += "--------第1希望--------n"
s = lottery("第1希望",s)
s += "--------第二希望--------n"
s = lottery("第2希望",s)
s += "--------第三希望--------n"
s = lottery("第3希望",s)
s += "--------第四希望--------n"
s = lottery("第4希望",s)
s += "--------決まらなかった人-----n"
cond = df_["decided"] == "Not yet"
dfM = df_[cond]
for j in dfM[keys[1:3]].values:
s += "%d : %s n" %(j[0],j[1])
print(s)
for i in range(len(fixNumber)):
print("定員: %d, 残り: %d, 項目: %s" %(fixNumber[i],restNum[i],groups[i]))
df_.sort_values(by="decided").to_excel("decided.xlsx",index=False)
希望が叶う確率を計算
僕の場合は, 希望調査の手順として第1段階, 第2段階に分けた. 第1段階で各グループで何名がどのグループを希望するかを全体に公開するのと, google formsに記載されているメールアドレス向けに現在の希望だと何%で希望が通るかを送信した. (メールの送信についてはこの章立てで計算された確率を元にして文章を作成してpythonで送信を行なった.)
ここでいう確率は, (第i希望)/(シミュレーションの数)によって定めた. 決まらなかった場合も同様に計算できる.
これは, 先ほどのlottery関数を用いればほぼ同様に書くことが出来る.
random.seed(1001)
nSim = 1000
dfCount = df.copy()
dfCount["1per"] = 0
dfCount["2per"] = 0
dfCount["3per"] = 0
dfCount["4per"] = 0
dfCount["Not"] = 0
for k in range(nSim):
if k % 100 == 0:
print(k)
restNum = fixNumber.copy()
df_ = df.copy()
df_["decided"] = "Not yet"
s = ""
s += "--------第1希望--------n"
s = lottery("第1希望",s)
s += "--------第2希望--------n"
s = lottery("第2希望",s)
s += "--------第3希望--------n"
s = lottery("第3希望",s)
s += "--------第4希望--------n"
s = lottery("第4希望",s)
s += "--------決まらなかった人-----n"
for i in range(1,5):
cond = df_["decided"] == df_["第%d希望"%i]
dfCount.loc[cond,"%dper"%i] += 1/nSim*100
cond = df_["decided"] == "Not yet"
dfCount.loc[cond,"Not"] += 1/nSim*100
del df_
del restNum
print("finish")
dfCount.to_csv("percent.csv",header=True,index=False)
メモリを軽くするために, 一回のシミュレーションが終わるたびに, df_ とrestNumのメモリを解放させてあげると良い. sは一回の抽選用に作成しているが, 希望が通る確率の算出時には使っていない.
これらのコードを用いれば, 大人数でgoogle fomrsで希望調査をして, グループを決定したい時に楽に決めることが出来るようになる.
———–雑感(`・ω・´)———-
抽選の結果は再現性を担保するために, seedを設定するようにした. でも, このプログラムを実行する人は気に入った抽選結果のseedで抽選するようにすれば, グループをある程度調整することが出来ることに注意. seedをプログラム実行する人以外の人が事前に決めとくようにするとさらに公平にすることが出来る.
僕がこのプログラムで一人一人に希望が通る確率を送ってあげると, ちょっとした楽しみが出来るだけじゃなくて, 希望が決まらない出ないように動いてくれる人は多かった. 結果的にみんな第2希望まででグループが決定したのは驚いた.(第1~4希望で決まらない人が出なくなるまでseedを調節したんだけどね…)
参考文献
(1) Jupyter notebookでpandasのDataFrameを綺麗に表示させる方法, https://qiita.com/hrsma2i/items/3970410d289542c5386c
(2) Pythonでメール送信, https://www.python.ambitious-engineer.com/archives/2034

コメント