
この記事では, pythonでSASを使うためのpythonのmodule, SASPyの環境設定と基本的な操作について書いていく.
SASPyはまだ開発中なため, この記事で書かれていることが使えなくなる場合がある. その場合は, [1]を参照のこと.
この記事はほとんどが参考文献の[1]から参照しているのでうまくいかなければ, そちらを確認すること.
SASPyとは?
SASPyは, jupyter notebook上でpythonとSASを同一のページで取り扱えるようにするmodule(pythonではパッケージをmoduleといっている). SASPyのメリットとしては, (i) pythonでデータを加工してSASで統計解析をする. (ii) SASでデータを加工して, pythonで予測をする. (iii)pythonにない機能だけをSASに任せる. といったことをプログラムを分けて書かなくて済むようになる. なのでお互いがお互いの良いとこ取りだけ出来るようになる.
また, SASPyは, 著作権が会社のSAS Institute Inc. なので, ライセンスの問題とか大丈夫と心配になる必要もない.
SASPyの核となるのはpythonのpandasというデータセットを扱うのに特化したフレームワークである. このpandasで取り扱うデータフレームをSASのテーブル構造と互換性を持つようにしている.
SASPyがどのようにして動いているのか, 以下の図を参照にして簡単なイメージだけ掴む. Pythonで保持しているSASPyを用いたデータフレームはSASのワークステーションにあるデータを表す(mydata). mydata.hpsplitというメソッド(pythonの用語)を用いるとSASPyはそのmethodを対応するSASのコードに変換する. そしてSAS Session WORK Libraryで処理がなされて, その結果がLST(last?の略, 多分…)とLOGという形式でpythonのdictionary構造の形で返される. このような流れでSASPyはpythonとSASの統合をjupyter notebook上で実現させている.

前置き
プログラミングをする時の一番の難所が環境設定であると個人的に思っているが, SASPyもその例に漏れない.
特に, SASを専門に使っている人にとってこのSASPyの環境設定での意味を理解するのは難しいかもしれない. それは, ファイルのパス構造やpythonがどこのファイルを探索してmoduleをimportしているかという仕組み, GitHubの特徴が分かってないとなぜそうする必要があるのか分からないからだ. とりあえずまずは動かすことを目標に.
また, 随時の操作がpythonのオブジェクト志向の書き方となっているので, pythonのコードに慣れていない人は一旦, pythonのプログラムの書き方に慣れておくと良い. 少なくともpythonでの”pandas”と”dictionary”については知っておくべきだろう.
僕の作業環境は以下である.
・PC : Mac Book Pro
・OS : macOS Mojave ver. 10.14.6
・仮想環境 : Parallels
・仮想環境上のOS : Windows 10 Home
・SASのversion : SAS 9.4 Windows版SAS
(仮想環境上に直接ダウンロードした)
・pythonのversion : 3.7.3
・SASPyのversion : 3.1.6
・Editor : Sublime Text
今回の記事の説明では以下の状態を前提とする.
・python, jupyter notebookがダウンロード済み.
・Windowsの環境でSASがローカルにダウンロード済み
・pipが使える状態. (pipはpythonのパケージマネージャー)
あと, 僕自身がMacユーザーでWindowsのコマンドプロンプトのコマンドをほとんど知らないのでファイル操作の部分はGUIを用いて行なっていく.
SASPyの環境設定
では, 手順に移っていく.
まずは, pipでSASPyをインストール.
pip install saspy
次にインストールしたsaspyのパスを確認する. python上で
import saspy saspy
と打てば,
<module ‘saspy’ from ‘C:¥¥Users¥¥[User Name]¥¥Anaconda3¥¥lib¥¥site-packages¥¥saspy¥¥__init__.py>
のようなものが出力される.
これからの説明は, jupyter notebook上から製品のSASにアクセスする設定をしていく. SASの製品の種類が違う人は, 違う設定をしなくてはいけないので[1]のConfigurationを読む必要が出てくる…
ローカルにSASがある人は以下の作業を行えばできる(はず..)
先に出力されたフォルダーまで行くと次のような構成になっている.
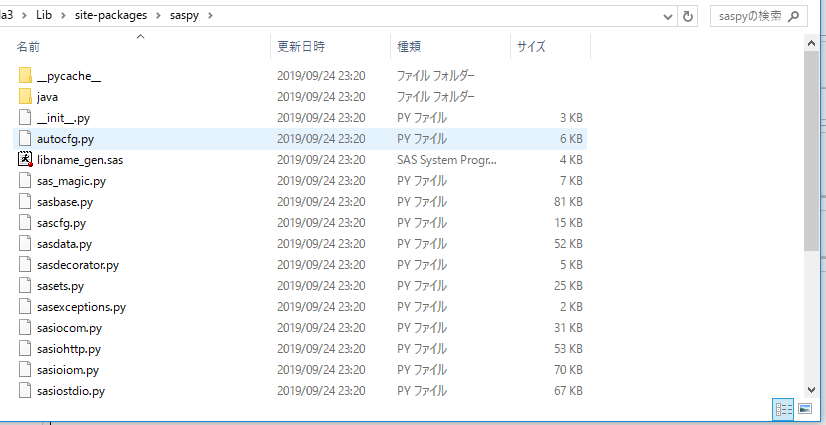
このファイルの中で, SASへのアクセスについて設定をする必要があるファイルは, “sascfg.py” である. しかし, pipの特性上, 一度saspyをアップデートすると, “sascfg.py”は上書きされてしまう. そこで自分用の”sascfg_personl.py”を作ってpythonが探してくれるpathの中においておく必要がある.
ローカルにSASがある人は非常に楽だ. デフォルトの位置にSASをインストールしていれば以下のpythonのコードを回すだけで, 自分用の”sascfg_personl.py”が作成される.
from saspy import autocfg autocfg.main()
出力された”sascfg_personl.py”は以下のようになる.
SAS_config_names=["autogen_winlocal"]
SAS_config_options = {
"lock_down": False,
"verbose" : True
}
cpW = "C:\Program Files\SASHome\SASDeploymentManager\9.4\products\deploywiz__94470__prt__xx__sp0__1\deploywiz\sas.security.sspi.jar"
cpW += ";C:\Program Files\SASHome\SASDeploymentManager\9.4\products\deploywiz__94470__prt__xx__sp0__1\deploywiz\log4j.jar"
cpW += ";C:\Program Files\SASHome\SASDeploymentManager\9.4\products\deploywiz__94470__prt__xx__sp0__1\deploywiz\sas.svc.connection.jar"
cpW += ";C:\Program Files\SASHome\SASDeploymentManager\9.4\products\deploywiz__94470__prt__xx__sp0__1\deploywiz\sas.core.jar"
cpW += ";C:\Users\[User Name]\Anaconda3\lib\site-packages\saspy\java\saspyiom.jar"
autogen_winlocal = {
"java" : "java",
"encoding" : "windows-1252",
"classpath" : cpW
}
import os
os.environ["PATH"] += ";C:\Program Files\SASHome\SASFoundation\9.4\core\sasext"
そしてこの”sascfg_personal.py”をホームディレクトリーの隠しフォルダーの中に置く. 絶対パスで表すなら, “C:¥Users¥[User Name]¥.config¥saspy¥sascfg_personal.py” になるようにする.
そのためにはまず, ホームディレクトリーまでいって(“C:¥Users¥[User Name]”)そこで, 隠しフォルダーの”.config”を作る.
(隠しフォルダーはフォルダーの表示タブに行って, 隠しファイルの場所にチェックを入れると見えるようになる. 隠しフォルダーの作り方 としては, “.”から始まるフォルダーはエラーが出るので一度, “.フォルダの名前.” のように”.”で最初と最後を挟んで作ってから, 最後の. を外すと作れる. )
“.config”の下に”saspy”のフォルダーを作って先のファイルを入れる.
これで環境設定は終了だ.
SASPyの基本的な操作
まずは,以下のコードをjupyter notebook上で打って正しく動くか確認しよう. encodingについてのエラーが出るが数値データだけをいじるならとりあえず気にしない.
上三行がSASPyを使う上でimport しておくべきものである. 最後の行でsasのセッションを開始し,連携がとれるようになる.
import saspy import pandas as pd from IPython.display import HTML sas = saspy.SASsession()

sasセッションへのcsvデータの読み込み
まずは,サンプルデータの作成を行う.
dfSample = pd.DataFrame(
{
"id":[i for i in range(1,16)],
"var1":[10*i for i in range(1,16)],
"var2":[60,70,55,67,43,94,34,70,100,43,63,75,34,67,86],
"var3":[5 + 2*i for i in range(1,16)],
"cate1":[0 for i in range(5)] + [1 for i in range(5)] + [2 for i in range(5)],
"cate2":[1 for i in range(8)] + [0 for i in range(7)]
}
)
dfSample.to_csv("sample_data.csv",index=False)
2通り方法がある.
一つは,直接csvデータをSASに読み込む方法. 引数のtableはsasのセッション内での名前を示すので入れておくと良い.
hr = sas.read_csv("./sample_data.csv", table="mydata")
二つ目は, pandasのデータフレームをsasのセッションに渡す方法. 最後の行は逆にsasのセッションからpandasのデータフレームに変換する方法を示している.
hr_pd = pd.read_csv("./sample_data.csv")
hr = sas.df2sd(hr_pd,table="mydata")
# SASのセッションからpandasのデータフレームへ
dfpy = sas.sd2df(hr.table)
jupyter notebook上でSASのコードを使う方法
2つ方法あり.
一つは, .submitの methodを使う方法.返り値としてdictionaryが来て,”LOG”の中にログ, “LST”の中に結果が入っている.
c = sas.submit("""
proc print data=mydata;
run;
""")
print(c["LOG"])
HTML(c["LST"])
もう一つはmagicを使う方法. %%SASのあとに, セッションの変数名を書いてあげるとセッション内に存在するデータにアクセスできるようになる. 今回の場合は, “sas = saspy.SASsession()”の”sas”が該当する.
%%SAS sas proc print data=mydata; run;
SASのテーブルに対して使えるメソッド
SASのテーブルに対して使えるpython方式のメソッドがいくつかある.
それをいくつか紹介.
display(hr.columnInfo()) display(hr.head()) display(hr.means())

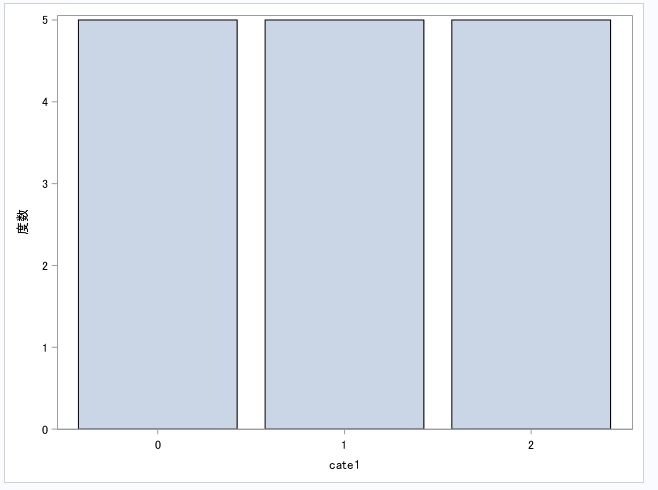
HTML(hr.bar("cate1"))
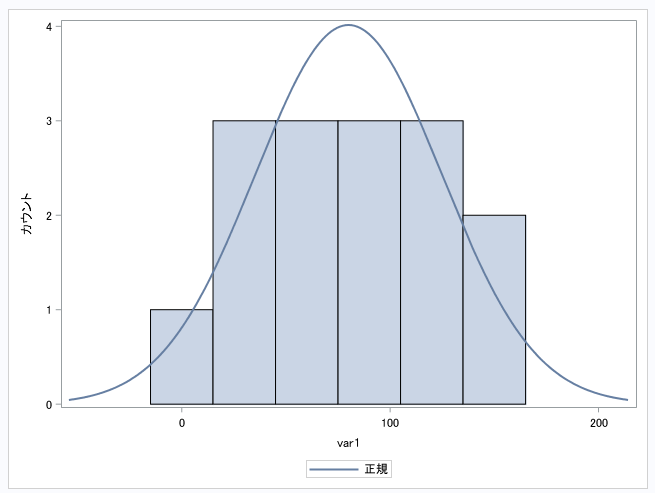
HTML(hr.hist("var1"))
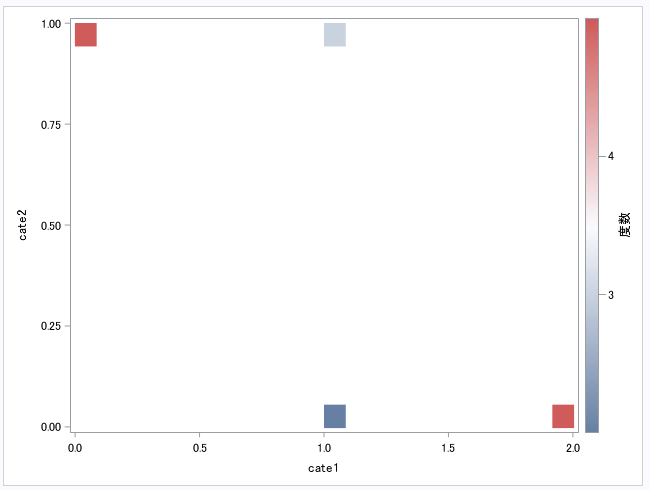
HTML(hr.heatmap("cate1","cate2"))
———-雑感(`・ω・´)———-
これで, SASのコードがpythonで使えるようになった!
最後のワンパスをSASで処理できるようになったのはでかい!
それにデータクリーニングもSASの方が書くの楽だから, 上手く使えれば楽になる予感!
後々に, SASPyの解析関連のコードも載せる予定!
参考文献
[1] SASPy Documentation Page, https://sassoftware.github.io/saspy/index.html
[2] Windows10 – ファイルの拡張子を表示/非表示にする, https://pc-karuma.net/windows-10-show-explorer-file-name-extension/
[3] Windowsで、”.(ドット)” で始まる名前のフォルダを作成したり、リネームしたり。 https://freefielder.jp/blog/2015/05/windows-dot-folder-name.html

コメント