
このページは,個人的にpandasの操作で調べたor用意しておいた方法の備忘録.まとまった内容については,別記事にする予定です.サイトマップのpandasの欄をご覧ください.
内容は出来たり,消えたりする場合があるのでご承知ください.
準備
データセットは基本的に,irisのデータ. 他の場合は適宜補足説明入れます.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(context="paper" , style ="whitegrid",rc={"figure.facecolor":"white"})
# for sample data
from sklearn import datasets
以下,データの加工.
dataset = datasets.load_iris()
dic = {}
for k,v in zip(dataset.feature_names,dataset.data.T):
dic[k] = v
df = pd.DataFrame(dic)
df["target"] = dataset["target"]
df["target"] = df["target"].replace({0:'setosa', 1:'versicolor', 2:'virginica'})
df.head().T
pandas の出力調整
pandasのデータフレームの出力を途中で途切れさせないための設定.あまりにもデータが多いと動作が悪くなるので注意.
pd.set_option('display.max_rows', 100)
pd.set_option("display.max_columns",100)
データフレームの削除方法
基本的な削除方法
行の削除. optionを指定しないと行削除となる.
a = df.drop(1) b = df.drop([0,1]) display(df.head(3)) display(a.head(3)) display(b.head(3))
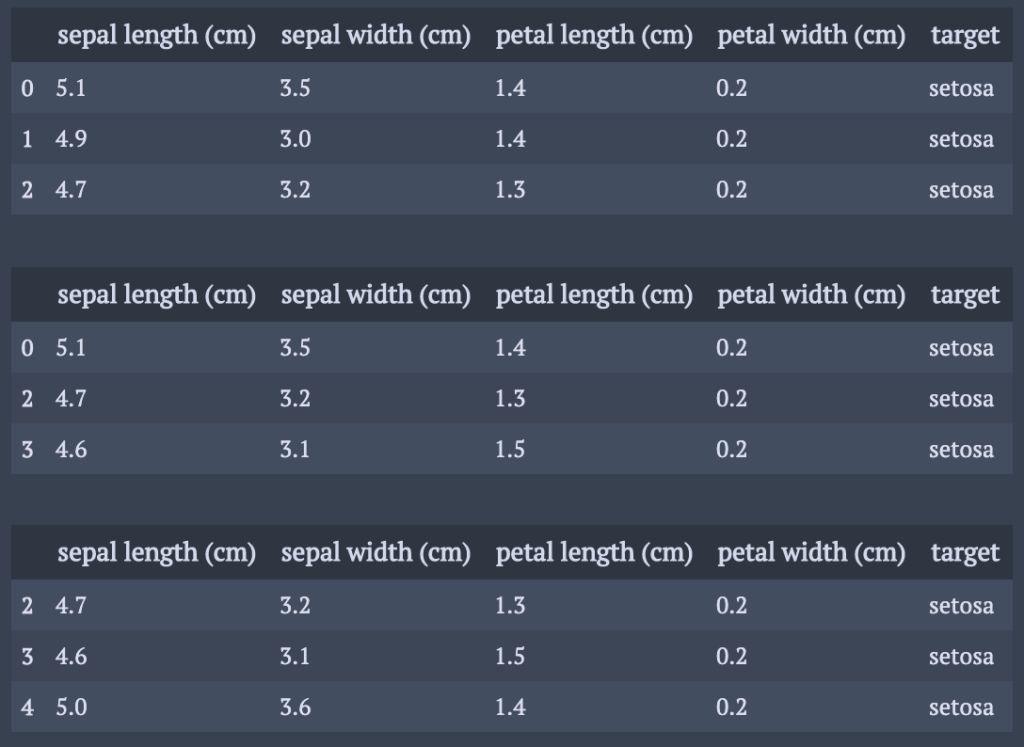
列の削除.
a = df.drop(columns="target") b = df.drop(columns=["sepal length (cm)","target"]) display(df.head(3)) display(a.head(3)) display(b.head(3))

delを用いる方法もあるが,複数のkeyを選択するとエラーが出るので,dropメソッドがオススメ・
条件に合致した行,列を削除
条件に合致した列の行の削除は,考え方を変えて,条件に合致しなかった行を抽出するアプローチが簡単.
*複数の条件に合致した行列の削除に関しては,複数の条件に合致する行列を抽出を参照のこと.
cond = df["target"] != "setosa"
a = df[cond]
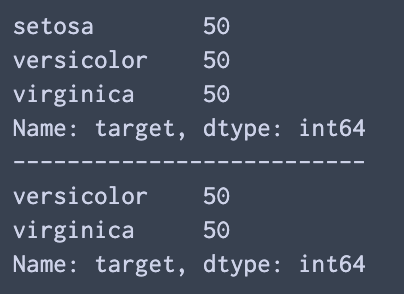
print(df["target"].value_counts())
print("--------------------------")
print(a["target"].value_counts())
欠損データの処理方法
pandasには欠損データを処理するためのdropnaが用意されている.
まずデータの欠損を含んだデータの作成.
# prepare dataframe containing missing data
np.random.seed(130)
df_ = df.copy()
for k in df_.keys():
rnd = np.random.choice([i for i in range(150)],10,replace=False)
df_.loc[rnd,k] = np.nan
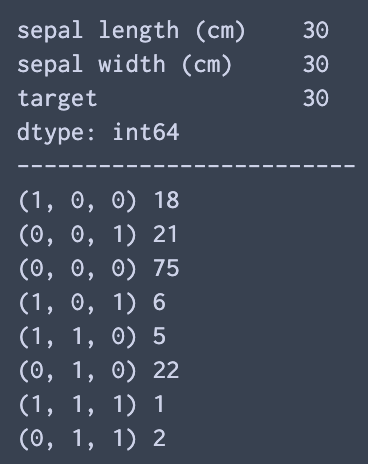
欠損パターンの確認.()内は各変数ないで欠損かどうかを示す.(1が欠損) ()の右に書かれている数字は,何件該当パターンがあったかどうか.
# check number of nan data for each key
print(df_.isnull().sum())
print("-------------------------")
# check nan pattern
from collections import Counter
def checkNan(df):
df_ = df.copy()
c = Counter()
for i in df_.index:
c[tuple(df_.loc[i,:].isnull().replace({False:0,True:1}) ) ] +=1
for k,v in c.items():
print(k,v)
checkNan(df_)
dropnaは,デフォルトではoptionの”how”が”any”になっているのでどれか一つでも欠けているとその行は消去される.threshで欠損を何個まで許すかも設定可能.
a = df_.dropna()
a2 = df_.dropna(thresh=2)
aAny = df_.dropna(how="any")
aAll = df_.dropna(how="all")
checkNan(a)
print("-------------")
checkNan(a2)
print("-------------")
checkNan(aAny)
print("--------------")
checkNan(aAll)

条件に合致した行,列に対する操作方法
複数の条件に合致した行,列の抽出方法
注意事項は二つ.
1つ目は,複数条件を組み合わせるときは,”&”, “|” を用いる.”and”, “or”を用いるとエラーが出る. python内部では, “&”, “|”はビット演算子と呼ばれる.
2つ目は, 条件を加えた上で特定のkeyにアクセスしたい場合は,locメソッドを使わなければいけない.さもないとエラーが出る.内部の処理に関しては,わかりやすい.
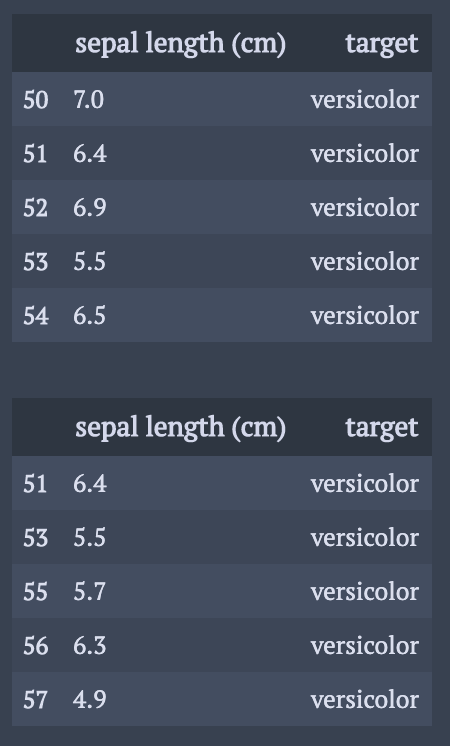
cond1 = df["target"] != "setosa" cond2 = df["sepal length (cm)"] < 6.5 display(df.loc[cond1, ["sepal length (cm)","target"]].head(5)) display(df.loc[cond1&cond2,["sepal length (cm)","target"]].head(5))
リストの要素のどれかを含む行の抽出
各要素に対して,リスト内包表記とany関数を求めて処理をすると条件部分を一行で書ける.
lis = ['setosa', 'versicolor' ] cond= df["target"].apply(lambda x: any([x == l for l in lis]) ) df = df.loc[cond]
それか,行単位で処理をする以下の方法が考えられる.
lis = ['setosa', 'versicolor' ]
cond = pd.Series(data = [False for i in range(df.shape[0])], index=df.index)
for l in lis:
cond = cond | (df["target"] == l)
df = df.loc[cond]
正規表現を用いた行,列の抽出方法
queryメソッドを用いる.queryメソッドでは,keyに"."を含んではいけないのと,数字は取り扱えないので注意.
*前出の(True,Flase)を用いた行,列の抽出方法はBool Indexメソッドという.
'''
Character method
str.contains(): 特定の文字列を含む
str.endswith(): 特定の文字列で終わる
str.startswith(): 特定の文字列で始まる
str.match(): 正規表現のパターンに一致する
'''
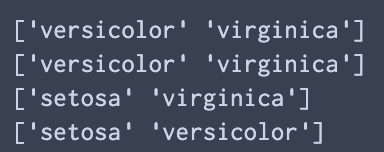
a1 = df.query(" target.str.contains('v')",engine="python")
a2 = df.query(" target.str.startswith('v')",engine="python")
a3 = df.query(" target.str.endswith('a')",engine="python")
a4 = df.query(" target.str.match(r'.+e.+o.+')",engine="python")
print(a1["target"].unique())
print(a2["target"].unique())
print(a3["target"].unique())
print(a4["target"].unique())
ちなみに,データフレームに欠損が入っているとエラーが出てしまうので,fillnaメソッドを用いて欠損を適切な文字か数字に飛ばしてからqueryメソッドを使うようにする.例としては以下のように.
df_ = df.copy()
df_.loc[[0,1,2],"target"] = np.nan
a1 = df_.fillna("vNan").query(" target.str.startswith('v')",engine="python")
print(a1["target"].unique())

データの置換
numpyの値の置換
numpyのmethodにあるデータは,文字列の複数の置換機能が揃っていない.だが,pandasの.replaceはdictionaryを与えれば可能.そこで,numpyを一度,pandasのデータフレームに変えてしまう手が考えられる.
a = np.array([1,2,3,4])
pd.DataFrame(a).replace({1:"a",2:"b",3:"c"}).values.T[0]

行,列の名前の置換方法
一部の名前の変更にはrenameメソッドを使う.
a = df.rename(index = {0:"new1",1:"new2"}, columns = {"target":"new_target"})
display(df.head(3))
display(a.head(3))

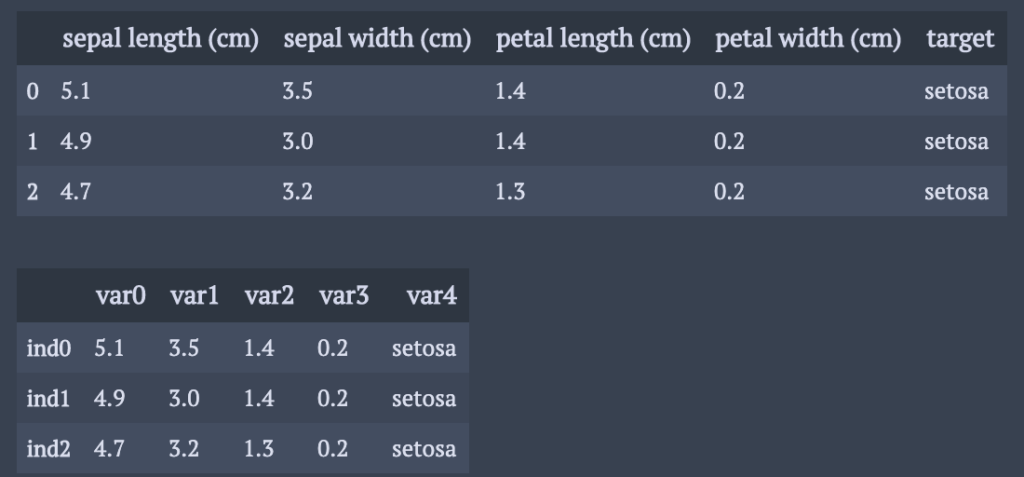
一気に名前を変更するには, indexとcolumnsに変えたい変数名を入れ込む.
a = df.copy() a.index = [ "ind" + str(i ) for i in range(150)] a.columns = ["var" + str(i) for i in range(5)] display(df.head(3)) display(a.head(3))
データフレームの結合
これは,図的にオプションと結合様式を結びつけて覚えていこう.
単純な結合
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
display(df1)
display(df2)
display(pd.concat([df1,df2]))

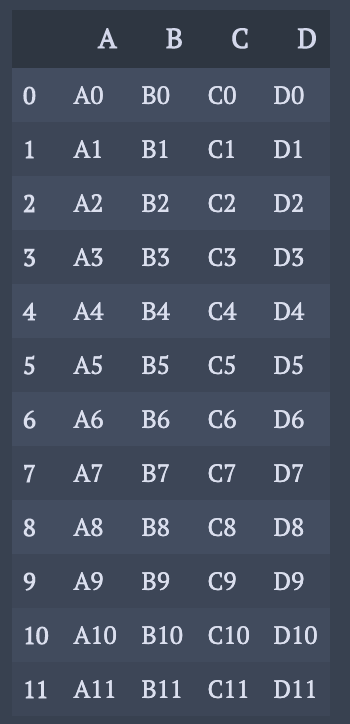
3つも結合可能.
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
pd.concat([df1, df2, df3])
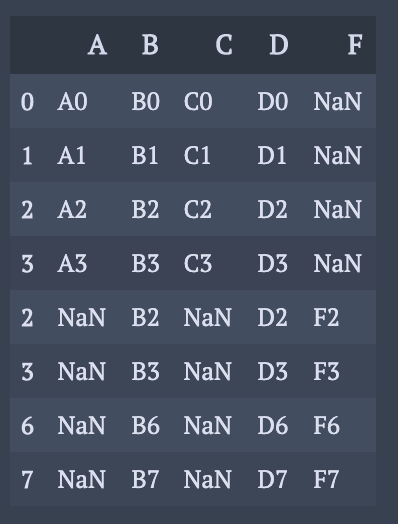
keyとindexが一致しない場合
outer結合. 一致しない部分には, 欠損値が生成される.
df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
'D': ['D2', 'D3', 'D6', 'D7'],
'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
pd.concat([df1, df4],sort=False)
このようなケースで問題となるのは,同じindexや同じkeyが存在するまま結合する場合だ.重複があるindexやkeyにアクセスすると抜き出すデータに区別が付けられなくなる.従って,結合する前にindexやkeyを振り直すのが一つの解決方法である.
水平方向に結合.
pd.concat([df1, df4], axis=1)
inner結合.共通部分だけを残す.
pd.concat([df1, df4], axis=1,join="inner")
groupbyの使い方
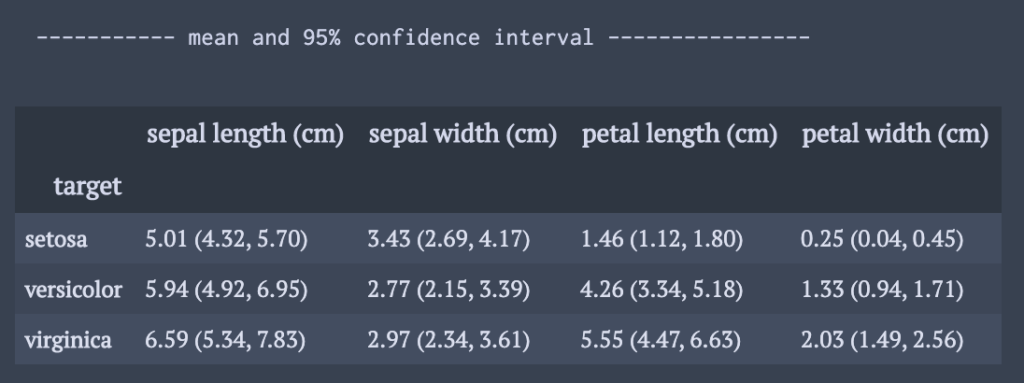
groupbyでグループごとの平均と信頼区間を見やすく表示
データフレームに平均と信頼区間を同時に入れる.
%演算子を使ってと表示したい桁数の調整.
def meanConf(df,by_ ):
df_ = df.copy()
g = df_.groupby(by=by_)
m = g.mean()
s = g.std()
r = m.copy()
for k in r.keys():
for i in r.index:
mm = m.loc[i,k]
ss = s.loc[i,k]
se = 1.96*ss
r.loc[i,k] = "%1.2f (%1.2f, %1.2f)"%(mm,mm-se,mm+se)
print("----------- mean and 95% confidence interval ----------------")
display(r)
meanConf(df,"target")
pandasデータフレームの変形
カテゴリカル変数を複数の二値変数に変形
get_dummiesメソッドを用いれば簡単にできる.
df_ = df.copy() dfDum = pd.get_dummies(df_["target"]) dfNew= pd.concat((df_,dfDum),axis=1) display(df_.head(5)) display(dfDum.head(5)) display(dfNew.head(5))
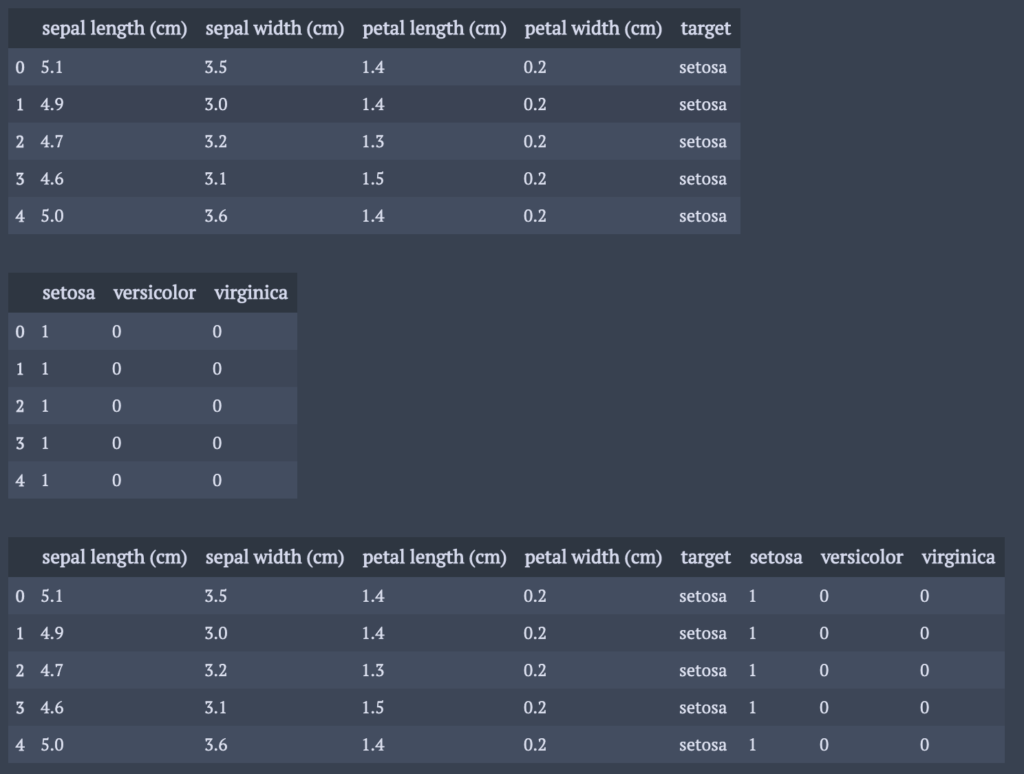
変形した後の変数の先頭に共通の文字を入れることは,一行追加するだけで実現可能.
df_ = df.copy() dfDum = pd.get_dummies(df_["target"]) dfDum.columns = ["var1_" + s for s in dfDum.columns] dfNew= pd.concat((df_,dfDum),axis=1)
参考文献
[1] Pythonで文字列を置換(replace, translate, re.sub, re.subn), https://note.nkmk.me/python-str-replace-translate-re-sub/
[2] [pandas]特定の条件を満たす行を削除する, https://linus-mk.hatenablog.com/entry/2019/01/10/003349
[3] Pythonのビット演算子(論理積、論理和、排他的論理和、反転、シフト, https://note.nkmk.me/python-bit-operation/
[4] Python pandas データ選択処理をちょっと詳しく <後編>, http://sinhrks.hatenablog.com/entry/2014/11/18/003204

コメント