
新しく投稿した記事の内容の方が使えます. こちらをどうぞ.
pythonでサイト検索順位を調べるプログラム|ブログ初心者用
背景
サイトを運営する上でそれぞれのページの検索順位を把握する必要がある. だが, 無料で検索するツールは有料版に比べて必要な機能が足りてない. 有料の検索順位ツールはいくつかあるけれども値段が高くなりがち.
-> 自分でpythonで検索順位ツールを作成すれば良い!
幸いにも先駆者たちがいるので参考にさせてもらう.
無料検索順位チェックツールがないから作った【KW無制限】
【Python】Seleniumを使ってコマンドラインでGoogleの検索順位をチェックする方法
準備
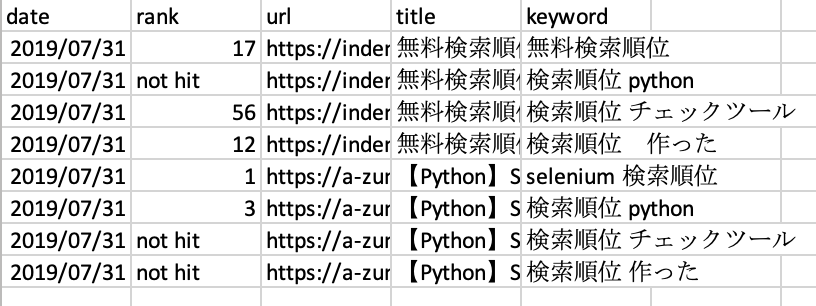
今回のコードで作成するのは, data_fileというフォルダーの下に日付.csv (Ex. 20190731.csv) を作成していく. 日付.csv の中にはdate, 順位, url, タイトル, 検索キーワードを入れる. 作成されるデータは以下の画像のようになる.
このブログは閲覧者数もランキングも低すぎるので, 上で紹介した2つのサイトを用いて解説させていただく.
プログラムを出来るだけ触らないようにするために, pythonの辞書型の形式で対象のサイトと検索ワードの組み合わせを書いたファイルを urls_keywords.txt で保存する. 今回は以下のようなデータを打ち込んだ. keyの部分が対象のサイトのurl, リストの部分が検索したいワードだ.
{
'https://indent.site/blog/1896':
[
'無料検索順位',
'検索順位 python',
'検索順位 チェックツール',
'検索順位 作った'
],
"https://a-zumi.net/python-selenium-google-rank-checker/":
[
"selenium 検索順位",
"検索順位 python",
"検索順位 チェックツール",
"検索順位 作った"
]
}
コードの解説
今回のファイルで使うmoduleを最初にimport する.
import os import time import datetime from bs4 import BeautifulSoup import requests import re import random import pandas as pd import ast
今回は, 1日につき1つのデータしか作成したくないので, 最初にすでにデータが出来ていないかを確認する.
today = datetime.date.today().strftime("%y%m%d")
savePath = "data_file/%s.csv" % today
if os.path.exists(savePath):
print("file already exists!")
return(0)
urlと検索ワードを渡すと, そのurlの検索順位を取得する関数を定義する. 戻り値としては形を整えたseriesだ. titleの部分は後のコードで入力するから関数内では未入力としている.
以下のコードの7行目が肝で, bs4_google.findAll('div', class_='BNeawe vvjwJb AP7Wnd')の部分でタイトルを含む要素を抜き出し, その一つ上のタグ内に含まれるリンクを i.parent.get("href") で取り出している.
注:以下の関数の7行目のdivタグ内のclass_の値は時間が経つとgoogle側で変更されるのではないかと睨んでいる(未確認). 変更されていた場合は, aタグを引っ張ってきてタイトルに該当する部分を見つけて適切なものに変更すること.
def search_index(my_url,keyword):
search_url_keyword = keyword
search_url = 'https://www.google.co.jp/search?hl=ja&num=100&q=' + search_url_keyword
res_google = requests.get(search_url)
bs4_google = BeautifulSoup(res_google.text, 'html.parser')
preUrls = [ i.parent.get("href") for i in bs4_google.findAll('div', class_='BNeawe vvjwJb AP7Wnd')]
urls = [re.sub(r'/url?q=|&sa.*', '', x) for x in preUrls]
if len(urls) == 0:
return(np.nan)
today = datetime.date.today().strftime("%Y/%m/%d")
url_index = 0
flag = False
for url in urls:
if my_url not in url:
url_index += 1
else:
url_index += 1
flag = True
break
if not flag:
url_index = "not hit"
series = pd.Series([today, url_index, my_url, '', keyword], index=df.columns)
return( series)
先程述べた urls_keywords.txt から順次データを取り出して順位を取得しデータフレームに追加していく. その際にgoogleの検索結果から一つもタイトル部分が抜け出せない場合は(divタグ内の値が変更された場合を想定) エラーを出してプログラムが終了するようになっている.
df = pd.DataFrame(columns=['date', 'rank', 'url', 'title', 'keyword'])
with open("urls_keywords.txt","r") as f:
urls_keys = ast.literal_eval(f.read())
for k,v in urls_keys.items():
# get title of the page
resBaseUrl = requests.get(k)
bs4BaseUrl = BeautifulSoup(resBaseUrl.content,"html.parser")
title = bs4BaseUrl.title.text
for vv in v:
series= search_index(k,vv)
if str(type(series)) != "<class 'pandas.core.series.Series'>":
print("Error!")
break
series["title"] = title
df = df.append(series, ignore_index = True)
print(series)
randomsleep = random.randint(70,100)
time.sleep(randomsleep)
df.to_csv(savePath,header=True,index=False)
これを検索順位チェックツールとして用いることができる. だた, 自分でいちいちプログラムを回さなければいけないのが難点.
取得したデータの可視化の方法については後日.
———-雑感(`・ω・´)———-
googleにこのツールを超短時間でアクセスし続けると以下のような文章が入ったエラーが出ることがある.
お使いのコンピュータ ネットワークから通常と異なるトラフィックが検出されました。このページは、リクエストがロボットではなく実際のユーザーによって送信されたことを確かめるものです。
ブラウザーで見ていれば, ロボットではありません, をチェックする場所が現れるのであろうが, 残念ながらpythonでアクセスしているとチェックすることができない. 僕が知る限りでは数時間放置すればこのエラーがなくなるそう… なのでエラーを出させないために, サイトの検索間隔は余裕を持って設定すること.
参考文献
(1) 【無料】検索順位チェックツール9選まとめ:2018年10月版, https://www.webtanguide.jp/column/free_seo_check_tool/
(2) 検索順位チェックツール11選!機能と料金をわかりやすく比較, https://seolaboratory.jp/74775/
・PythonとBeautiful Soupでスクレイピング, https://qiita.com/itkr/items/513318a9b5b92bd56185
・python3 文字列を辞書に変換, https://qiita.com/lamplus/items/b5d8872c76757b2c0dd9
・バックグラウンド実行で時間短縮しよう!! , https://qiita.com/alancodvo/items/15dc36d243e842448d33

コメント