
データ解析をするときや依頼されたときに, まず, 手元にあるデータがどんな特徴を持つのか, どんな変数があって, 平均や欠損値がどれくらいあるのかなどを把握する必要がある.
ここでは, pythonのpandasのライブラリを用いて, データ解析をする際にデータの特徴を把握するためにルーティンワークとして行う内容を紹介する.
動作環境はjupyter notebook上であることを前提とする.
用いるデータは, スイス繁殖鳥類調査MHBの1999年から2007年まで8年間のヒガラの観測数に関するデータを使って行う. (.txt形式)
デフォルトの設定
以下のコードはsnippetとして登録していつも用いている.
sns.set の行は, jupyter notebookのthemeを暗めのものにしているとplotする際に背景が暗くなってしまうのでそれを防ぐために用いている. gridがあったほうがgraphは見やすいというのもある.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(context="paper" , style ="whitegrid",rc={"figure.facecolor":"white"})
以下の2行は, pandasの出力が途中で途切れないようにするためのコード.
pd.set_option('display.max_rows', 500)
pd.set_option("display.max_columns",500)
データの型と値のパターンと特徴を把握する
データを df に格納. dataframeの行列の確認.
df = pd.read_table("tits.txt",sep = "t")
df.shape
dataframeのkeyと具体的な値をいくつかみる
print(", ".join(df.keys()))
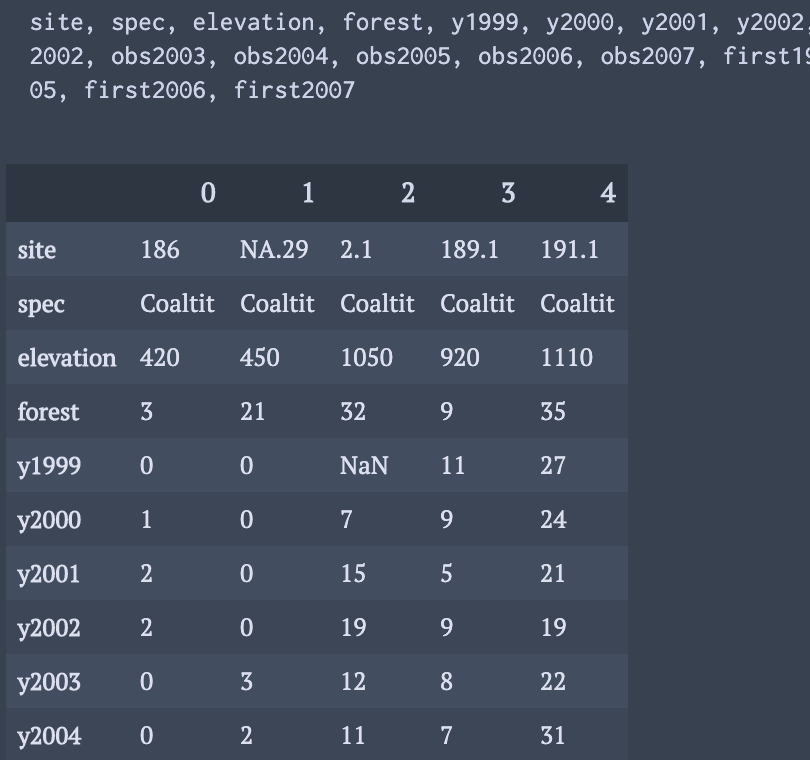
display(df.head().T)
keyごとに取る値の種類を確認する.
categorical data が多いいデータを確認する際に有効.
for key in df.keys():
print("-----------" +key +"-------------")
print(df[key].unique())

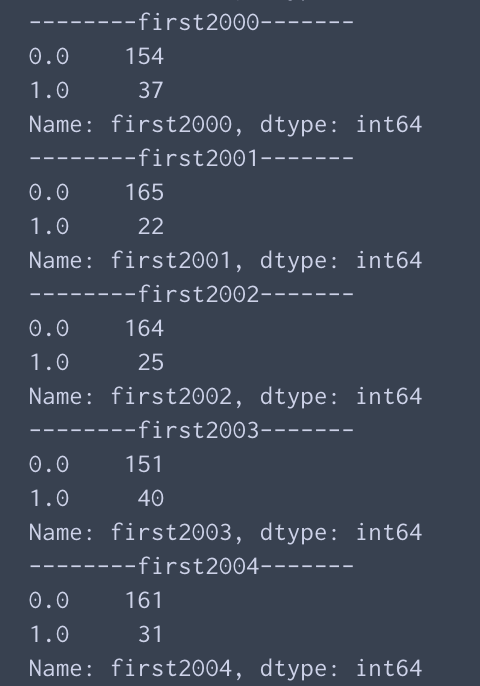
keyごとに値の種類とその出現頻度を調べる
from collections import Counter
for k in df.keys():
print("--------%s-------" %k)
print(df[k].value_counts())
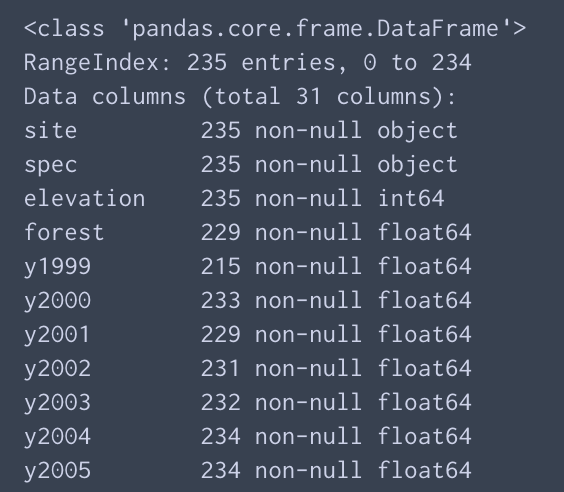
それぞれのkeyごとの有効なデータの数とkeyに格納されているデータの型の一覧
df.info()
数字が格納されているkeyに関して, 基本統計量の算出
display(df.describe().T)

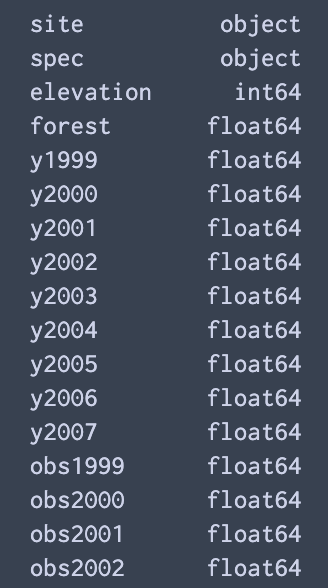
各keyのデータの型だけチェックする方法
df.dtypes
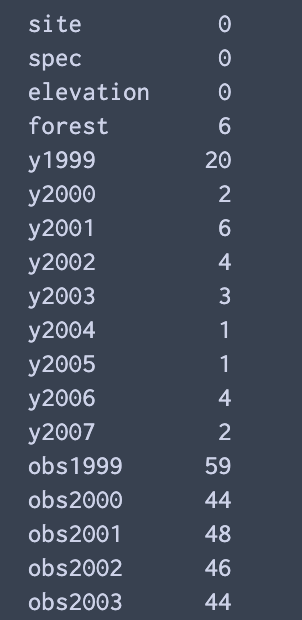
NaNのデータの確認
keyごとに何個NaNが存在するかを調べる
np.sum(df.isnull(),axis=0)
NaNのパターンを複数のkeyにしたがって調べる.
今回は全てのkeyに関して.
# check nan pattern
from collections import Counter
c = Counter()
for i in df.index:
c[tuple(df.loc[i,:].isnull().replace({False:0,True:1}) ) ] +=1
for k,v in c.items():
print(k,v)

———-雑記(`・ω・´)———-
これらのデータを図示して表示するのも良い. でも, 文字として確認すると同時に多くのデータに関して見ることができるね.

コメント