
statsmodelsでLogistic regressionやLog binomial regressionした結果を解釈するときに,数字やカテゴリーが多くなりすぎると解釈がとても大変になる.そこで,meta-analysisなどで頻繁に使われるforest plotを,このケースでも適応させることが目標となる.
ただ,Pythonで簡単にForestplotを作れる良いPackageはあまり存在しない.
Meta-analysisの図の作成ならば,PythonMeta, PyMARE, NiMARe などが存在する.
また,以下のスレッドで図を簡単に確認出来るが,zEPIDとstatsmodelsにもforestplotを作成する機能は存在するが,あまり汎用的ではない.(zEPIDはあまり調べていないがちゃんと調べればそこそこのものを作成出来そうではある.)
・How can I create a forest plot?
そこで,MyForestPlotというPackageを作成した.DocumentationにQuckstartやGalleryが載っているので,本格的に使用するならそちらを参照すること.
・MyForestPlot documentation
この記事では,どんなことが出来るのか,どんな機能を実装していく予定なのか,パッケージ作成のときの工夫について書く.
何が出来るのか?
その1.statsmodelsの結果をnp.expかけて,かつ,Categoryとその要素,それぞれのCategoryのnobsが手に入る.
Forestplotの作図も良いが,個人的にはこちらの機能は後々汎用的に使っていくのではないかと思う.statsmodelsのfittingまでは良いがそのresultsを更にいじる機能が弱い.そのため,forestplotを作図するための前段階としてデータ整形が必要になった.以下のコードでresultsが好ましい形になる.dataはtitanicのデータ,resはlogistic regressionの結果が格納されている.
order = ["age", "sex", "embark_town"]
cont_cols = ["age"]
categorical = {"embark_town": ['Southampton', 'Cherbourg', 'Queenstown']}
df_sum = mfp.statsmodels_pretty_result_dataframe(titanic, res,
order=order,
cont_cols=cont_cols,
fml=".3f",
)
df_sum

その2. matplotlibの機能を用いて,細かいForestPlotの図の調整をしながら作図可能.
これに関しては,機能の中心のためDocumentationを読んで欲しい.以下には,どんな図が作成出来るのか,完成品だけ幾つか載せておく.
基本的な図.
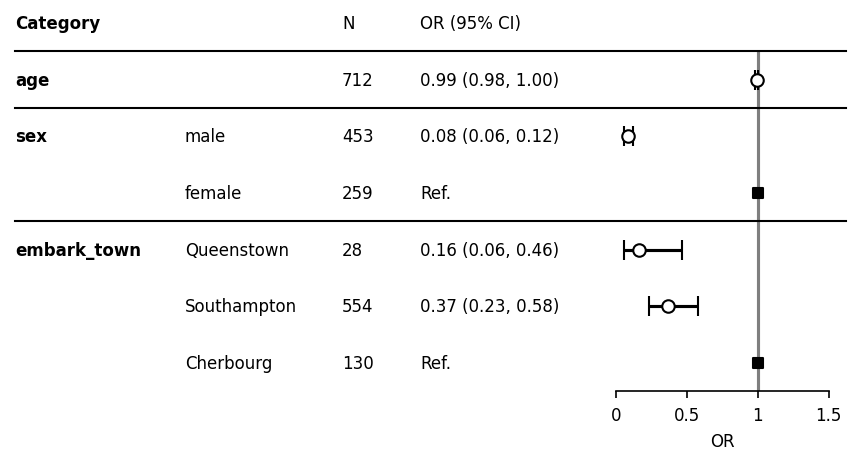
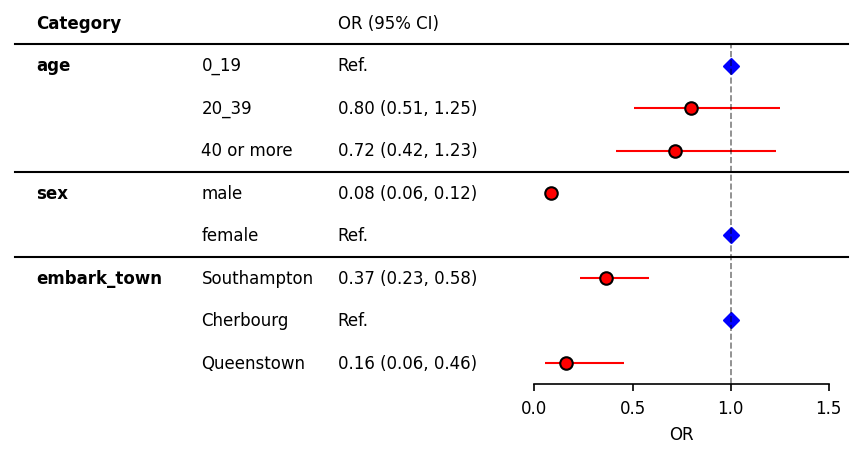
色や線のデザインを変えたversion.
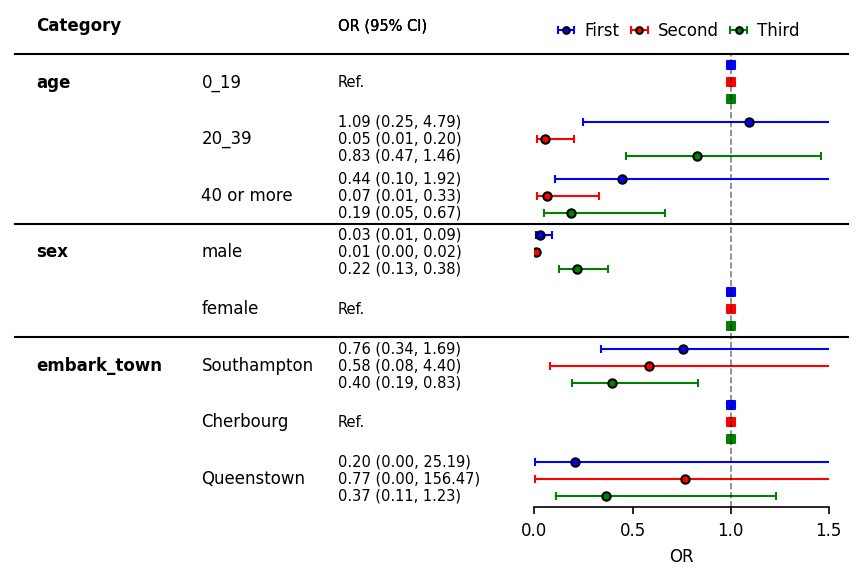
層別化して解析した結果をまとめたversion.
以下の機能は,追加で実装する予定だ.
・横並びのCategoryをItem群の少し上に並べるようにする.
・boxplotの区間が幅を超えたときに矢印を描くようにする.
・ForestPlotを何バージョンか横に並べて描写出来るようにする.
パッケージ作成の工夫
一つは,statsmodelsのresultsを適切に加工してDataframeとして用意することが大事だった.他のプログラムで出力されるデータも,エクセル上で加工することで似たような形に持っていくことはそんなに難しくない?はずなので,そのデータ形式をそのまま図示することに努めた.
ForestPlotのベースとして,text部分と図の部分をGridspecで2つ用意して作業したことが良かった.また,text部分のx軸を0から1にfixすることで配置の用意さを少し上昇させた.
y軸を正で振っていくのではなく,マイナスで振っていくことは肝要だ.さもないとDataframeの順番が完全に逆順になってしまう.座標をマイナス側を用いることで煩雑なコードを書くことを避けられた.
以上.宣伝用の記事でした.
———-雑感(`・ω・´)———-
Documentation pageには再現性の都合上,カテゴリーの数がそんなに多くないものが用いられているが,実際に数十項目ある解析結果をこのパッケージに流し込むと,綺麗な図が出てきて,やはりパッケージ作っとくと嬉しいことあるな,と自己満足に浸ることが可能.

コメント