
この記事では,シェルスクリプト(bash)のコマンドであるgrepを用いれば,医学部のCBT,国試対策をちょっと工夫して行うことが出来ることを示す.
目的
本記事で示す勉強の工夫の目的は,疾病ごとに特徴をまとめられている諸参考書にあまり載っていない,症状が上がったときに鑑別に挙がる疾患をひたすらまとめていく方法である.
データの入力
入力する際は,以下の例のようにする.
赤沈亢進: [鑑別] 亜急性甲状腺炎, <免疫> シェーグレン症候群,SLE,関節リウマチ(RA), <血液> 多発性骨髄腫, JAK2: [鑑別] 原発性骨髄線維症,真性赤血球増多症(PV),
すなわち,
症状名の後に,”:” をいれ,[鑑別] と書く.そのあとに疾患の名前を”,”区切りで入力していく.疾患領域や階層性を持たせたい場合は,”<属性名>”で入力する.可読性を保つために,xml形式のように終わりの区切りをつけない.次の属性名か,疾患名が出てくるまでを,その属性のフィールドとする.
このように入力するメリットとしては,
・入力が直感的,
・入力しながら,勉強が出来る.
・次のgrepの作業時に,そのまま該当部分を表示させても十分に読むことが出来る.
ということが挙げられる.
grep の出番
上のような形式,(または,他の定式化した方法) にしておけば,grep で言葉を検索することが出来る.
肝になるコマンドは,以下の med_grep である.”.bashrc” なりに書き込んで使えるようにする.
以下は,僕の環境(Ubuntu)でのコマンドである.
function med_grep(){
echo "-------------------------------"
C_op=${2:--C10}
grep $1 /home/akitoshi/Desktop/medicine/words_connections.txt $C_op -i
}
このコマンドを打つと,まず最初に区切りの文字列が出力される.
そして,引数として何も指定しないと,該当ファイル(words_connections.txt)から,検索ワードの行前後10行を表示するものだ.
シンプルだけど,強力だ.
以下は,僕が作成したファイルで, med_grep ANCA と打ったときの出力結果.
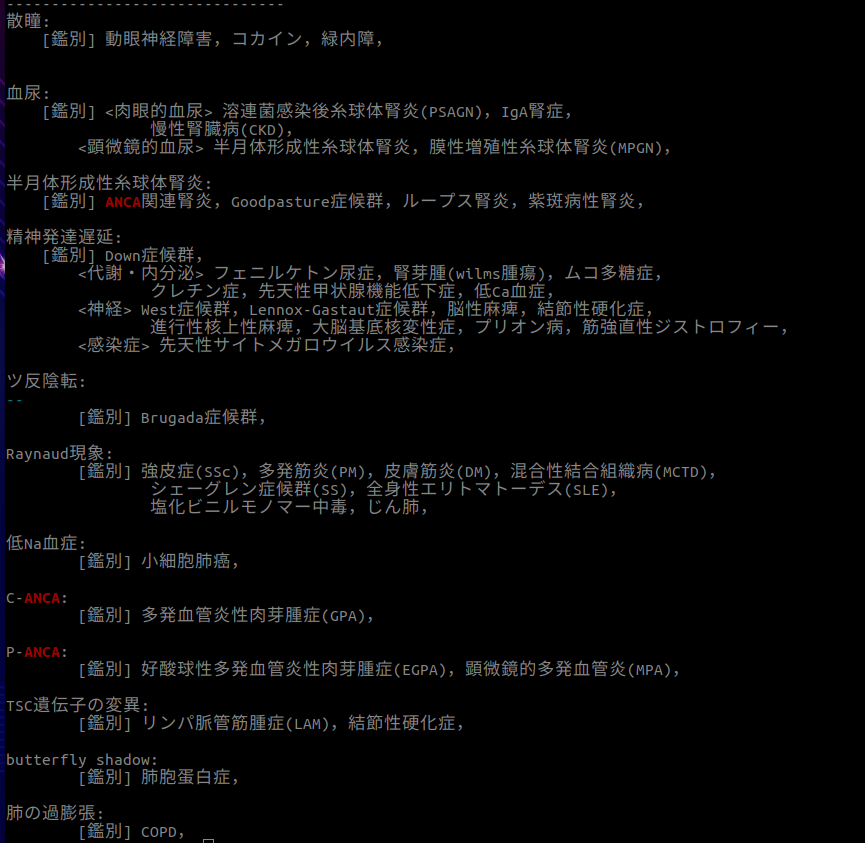
検索対象のデータは卒試,国試勉強中に作成中なので,ある程度,出来たら上げるかもしれません.
以上.
———-雑感(`・ω・´)———-
・ここで示したデータで入力をしていけば,後にプログラムで定式的にデータを引っ張り出すことが出来る.僕は,pythonでdictionaryに保存して,pygraphvizで,症状と疾病をつなげた大規模グラフの作成を睨んでいる.完成したらブログ書きたいと思っている.
・今回のideaは,Linux のコマンドラインでオフライン英和辞書で書かれている内容を基にしている.シンプルだけど,個人的には有用.

コメント