
pythonでchoroplethを描きたく調べていたが,foliumばかりだった.しかし,geopandas単独でも求めるchoroplethを作成することが分かったのでメモをする.
matplotlibの取り扱いになれているならば,geopandasの方が良いかもしれない.
コードは,git clone https://github.com/akitoshiblog/geopandas-choropleth.git で手に入る.
下準備
まずは,北海道の市区町村単位のポリゴンデータを入手する必要がある.
国土地理院の国土数値情報ダウンロードから地図情報を入手する.
geojsonやshp形式など様々な形式でデータを入手することが可能だ.
もし,全国の市区町村単位のデータを用いる必要があるならば,https://github.com/niiyz/JapanCityGeoJsonから入手することも可能である.(データサイズは大きいが.)
今回は,行政区域のデータ から,北海道の部分をダウンロードし,geojson形式のファイル名をダウンロードをhokkaido.geojsonとしておく.
また,最初に以下の4つのmoduleをimportしておく.
import geopandas as pgd import matplotlib.pyplot as plt import japanize_matplotlib import mojimoji
振興局ごとの色分け
データを以下のコードでダウンロードする.日本語データを取り扱うので,エンコーディングにshift-jisを指定するのを忘れずに.
geo_df = gpd.read_file("./hokkaido.geojson", encoding="SHIFT-JIS")
後は,組み込みのplotを用いれば chroplethが完成.
geo_df.plot()
ここから,振興局単位で色分けすると,以下のような図になる.
Legendのパラメータの調整をする場合は,geo_df.plot内にlegend_kwdsの形で渡して上げればよい.
fig = plt.figure(figsize=(5,3),dpi=150)
ax = fig.add_subplot(111)
legend_kwds = dict(bbox_to_anchor=(1, 0.98), loc='upper left', borderaxespad=0, fontsize=8,frameon = False)
ax = geo_df.plot(column="N03_002",legend=True, legend_kwds=legend_kwds,ax=ax, cmap="tab20")
plt.axis('off')
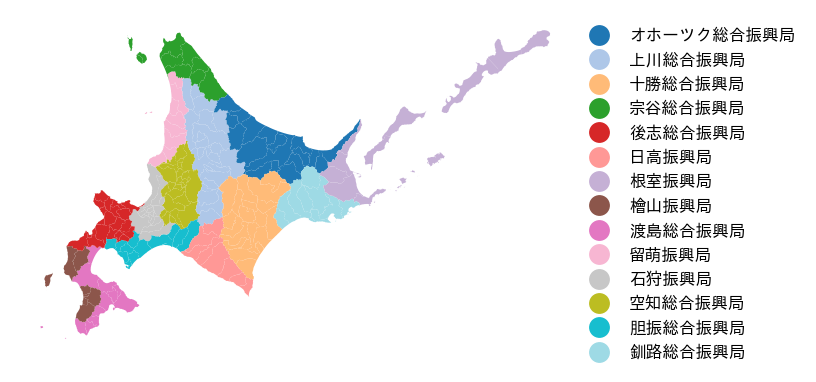
これで,振興局単位で色分けが出来た.
あとは,このデータフレームに対して,数値データを突合すれば場所ごとの色分けも行うことが可能である.
振興局ごとの人口の描写
人口データに関しては,北海道庁のホームページからH27の国勢調査を入手した.
そのままの形では使えないので,今回は振興局の総計の部分だけ抜き出してデータを取り扱う.
また,カラム名も扱いやすい名前に変更しておく.
githubのhokkaido_population.xlsのシートmunicipalityに今回用いるデータがある.
geopandasのデータカラムで対応するのは,N03_002で,その要素名と国勢調査の要素名を一致させる必要がある.幸いにも最初の2文字で比較すれば対応関係が作れるのでその処理を行う.
location = "N03_002"
df = pd.read_excel("./hokkaido_population.xls", sheet_name="municipality")
df["municipality"] = df["municipality"].apply(mojimoji.han_to_zen).str.rstrip("計")
rep_dic = { }
for c1 in geo_df[location].unique():
for c2 in df["municipality"].unique():
if c1[:2] == c2[:2]:
rep_dic[c2] = c1
df[location ] = df["municipality"].replace(rep_dic)
geo_merged = pd.merge(geo_df, df, on=location)
これで,geo_mergedのデータフレームに使用するデータが整った.振興局単位に対するポリゴンデータがないので,その振興局に属する市町村全てを同じ色で塗りつぶす手法をここでは取る.
あとは,以下のコードで人口を表示することが可能.dividerなどは,colorbarの大きさを調整するのに必要だ.
from mpl_toolkits.axes_grid1 import make_axes_locatable
fig = plt.figure(figsize=(8,6),dpi=150)
ax = fig.add_subplot(111)
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.1 )
ax = geo_merged.plot(column="H27_population_total",ax=ax, cmap="rainbow", cax=cax,
legend=True, ) # scheme="quantiles"
ax.set_title("振興局単位での人口", fontsize=10)
ax.axis("off")
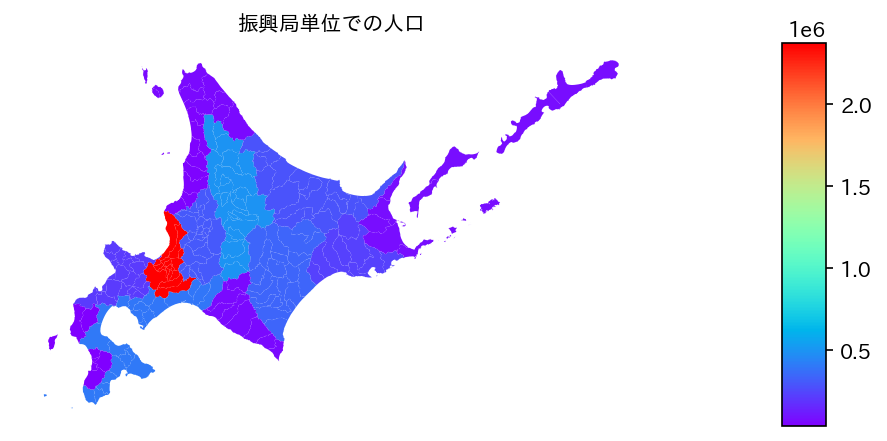
振興局ごとの人口密度の描写
人口密度も同様に描写可能.今回はタイトルと,legend label,それと範囲の指定をしてみる.範囲の指定は複数の図を比較する際に色を統一させたいときに必要になる.vmin, vmaxを指定してあげるだけでok.
fig = plt.figure(figsize=(8,6),dpi=150)
ax = fig.add_subplot(111)
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.1)
cax.tick_params(labelsize=8)
ax = geo_merged.plot(column="H27_population_density" ,ax=ax, cmap="rainbow", cax=cax,
legend=True, legend_kwds={"label":"person/km^2"},vmin=0, vmax=700)
ax.set_title("振興局単位での人口密度", fontsize=10)
ax.axis("off")
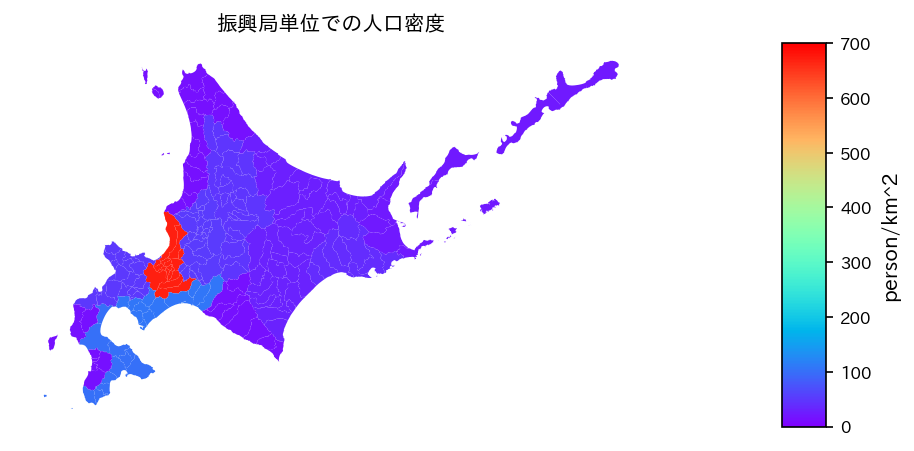
最後に,場所が多くなってると連続値は結局どの辺りの値かよく分からなくなる.
そこで,連続値をカテゴリカルにして表示したくなる.これは,schemeパラメータで指定可能だ.schemeを指定するとmapclassifyというパッケージでカテゴリカル化する.kで区分の数を指定可能.
fig = plt.figure(figsize=(8,6),dpi=150)
ax = fig.add_subplot(111)
legend_kwds = dict(bbox_to_anchor=(1, 0.98), loc='upper left', borderaxespad=0, fontsize=8,frameon = False)
ax = geo_merged.plot(column="H27_population_density" ,ax=ax, cmap="rainbow", scheme="quantiles", k=4,
legend=True,legend_kwds = legend_kwds)
ax.set_title("振興局単位での人口密度", fontsize=10)
ax.axis("off")

———-雑感(`・ω・´)———-
これで,choroplethを自在に書ける! 場所ごとに名前を直接書き込みたいときは,どこかの座標データを持ってきて,テキストアノテーションで書き込めば良い,はず.
道央道南が人口密度高めなのが分かりますね.
参考文献
- geopandas official site, Mapping Tools
https://geopandas.org/mapping.html - Indexing by GeoJSON Properties
https://plotly.com/python/choropleth-maps/ - 【Python】foliumで日本地図と市町村の線を描く
https://qiita.com/sasaki_K_sasaki/items/cbe6cd8b85c6a0e62ff3 - JapanCityGeoJson 2016
https://github.com/niiyz/JapanCityGeoJson - GEOJSON
https://geojson.org/ - 小学校の在籍人数を地図上にマッピングする(Folium、GeoPandas利用)
https://qiita.com/Gyutan/items/f9b365d88a1ff89671f0 - Analyzing geospatial data with GeoPandas and plotly
https://medium.com/@sukantkhurana/analyzing-geospatial-data-with-geopandas-and-plotly-b13dedcbe466 - How to change the font size of the color bar of a GeoPandas choropleth plot
- ProPlot, colorbars and legends
https://proplot.readthedocs.io/en/latest/colorbars_legends.html - Colorbar on Geopandas
https://stackoverflow.com/questions/36008648/colorbar-on-geopandas - Plot chloropleth with consistent `legend` and bins #1019
https://github.com/geopandas/geopandas/issues/1019

コメント