
この記事では,Pythonのパッケージの一つであるStatsmodelsを用いたLogistic RegressionでOdds Ratioを計算する方法を紹介する.また,Logistic regressionを行うまでのクリーニング方法に関しても示唆を与えるような内容にする.
ここで用いたコードは,https://github.com/akitoshiblog/statsmodels_odds_ratio からアクセス可能.
データの準備
データの準備.pandasとstatsmodelsがあれば良い.
import pandas as pd import numpy as np import statsmodels.formula.api as smf import statsmodels.api as sm
サンプルデータはstatsmodelsの中に存在するthe American National Election Studies of 1996のデータを用いる.データの詳細に関してはリンクに飛ぶと確認することが出来る.
欠損データが混入したデータセットも使用出来るように,欠損なしのデータに対しても欠損データがあるようにする.
df = sm.datasets.anes96.load_pandas().data # insert missing values np.random.seed(130) rnd1 = np.random.choice(df.index,50,replace=False) rnd2 = np.random.choice(df.index,50,replace=False) df.loc[rnd1,"age"] = np.nan df.loc[rnd2,"educ"] = np.nan
データの特徴の確認
それぞれの変数が連続値かカテゴリカルなのかを判別する.実際のデータ解析においてはデータ収集時にデータ型は判別されているはずなので,変数表なりを参照する.ここの方法はデータから判別するための示唆を得るための方法.また,異常値が混在することは多々有るためその確認も兼ねる.
for c in df.columns:
print(c)
print(df[c].unique())
print("="*50)
欠損データがどれくらい存在するかを確認する.また,そのパターンも把握出来るようにする.
for c in df.columns:
print(c)
print(df[c].isnull().sum())
print("="*50)
またそのパターンも把握出来るようにする.(最新のpandasのversionでは,.value_countsを複数行に対して行えるようになっている.言い換えれば,pandasのSeriesだけでなくDataFrameに対しても.value_countsが実装された.)
df.isnull().value_counts()

データエンジニアリング
the American National Election Studies of 1996のデータエンジニアニングを行う.今回はデータクリーニングと実際の実装を優先するため,因果推論を考えないが,実際の解析の際には入れる説明変数については因果推論を考慮した上で選択すること.
c = "TVnews"
dfM = df.copy()
dfM[c] = (dfM[c]
.mask(df[c] <=7, "frequent")
.mask(df[c] <=5, "moderate")
.mask(df[c] <=3, "seldom")
)
c = "income"
dfM[c] = (dfM[c]
.mask(df[c] <= 24, "17-24")
.mask(df[c] <= 16, "9-16")
.mask(df[c] <= 8, "0-8")
)
# include missing
c = "age"
dfM[c] = (dfM[c]
.mask(df[c].isnull(),"missing")
.mask(df[c] <=100, "81-100")
.mask(df[c] <=80, "61-80")
.mask(df[c] <=60, "41-60")
.mask(df[c] <=40, "19-40")
)
c = "logpopul"
dfM[c] = (dfM[c]
.mask(df[c] <= 9, "high")
.mask(df[c] <= 4.70, "moderate high")
.mask(df[c] <= 3.09, "moderate low")
.mask(df[c] < 0.09, "low")
)
c = "PID"
cates= ["Strong Democrat","Weak Democrat","Independent-Democrat"
,"Independent-Indpendent", "Independent-Republican"
,"Weak Republican", "Strong Republican"]
rep_dic = {i:c for i,c in enumerate(cates)}
dfM[c] = dfM[c].replace(rep_dic)
c = "selfLR"
cates = ["Strong Democrat","Weak Democrat","Independent-Democrat"
,"Independent-Indpendent", "Independent-Republican"
,"Weak Republican", "Strong Republican"]
rep_dic = {i:c for i,c in enumerate(cates)}
dfM[c] = dfM[c].replace(rep_dic)
# include missing
c = "educ"
cates = ["1-8 grades","Some high school", "High school graduate"
,"college", "College degree", "Master's degree", "PhD"]
rep_dic = {i:c for i,c in enumerate(cates)}
rep_dic = {**rep_dic, **{np.nan:"missing"}}
dfM[c] = dfM[c].replace(rep_dic)
上のコードの補足としては,pandasのmethod chainingとmaskを有効活用するとコードがかなりスッキリすること.また,連続値からカテゴリカルへの変換には pd.cut という関数があるが,cutoff値を特殊なものにしたかったり欠損値の取り扱いに特殊な操作をしたいといったケースに対応出来ないため,maskとreplaceを中心にdata engineeringを行う.
pandasのmethod chainingの詳細に関してはこの記事を参照のこと.
・[Python] Pandasのメソッドチェーンを活かしたデータクリーニング
欠損値がこれで消えたかどうか,また,値が意図したものに変換されているかどうか,ここで再度確認しておくと良いだろう.
Logistic regression
Logistic regressionには,smf.glmを用いる.この関数のformulaを持ち入れば,わざわざ pd.get_dummiesを用いてカテゴリカル変数をOne hot encodingして,かつベースラインを抜くという操作をしなくて済む.
また," + ".join(dfM.columns) を用いて,カラムを + で結合すれば,カラム名をわざわざ手打ちする必要もない.
今回は,以下の"vote"を結果変数,他のいくつかを説明変数,また,ageのreferenceを41-60にして線形予測子を構成する.
formula = "vote ~ TVnews + selfLR + PID + C(age, Treatment('41-60')) + educ + income + logpopul"
res = smf.glm(formula=formula,data=dfM, family = sm.families.Binomial()).fit()
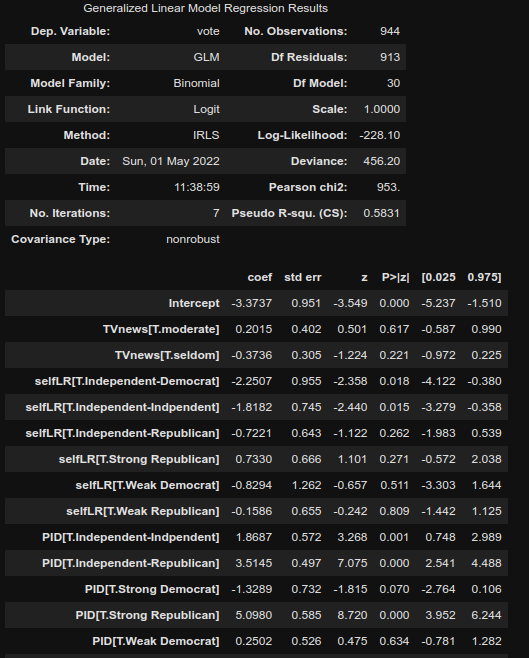
結果の確認のためには,res.summary() とres.summary2() がある.後者の方法だとAIC, BICを確認することが可能.ただし,後者のBICはdeviance based methodologyなのでlog-likelihood basedで算出される結果とかなり解離がある.以下が res.summary()の算出結果.
AIC, BIC, log-likelihood basedなBICのアクセスの仕方は以下の通り.
print(res.aic) print(res.bic) print(res.bic_llf)
Odds Ratiosは係数をnp.expで囲えば手に入る.論文用に,綺麗な形で整頓したいので以下のようにまわすと,"odds_pretty"に綺麗な信頼区間付きのodds ratiosが手に入る.
odds = np.exp(res.conf_int())
odds["odds"] = np.exp(res.params)
odds["odds_pretty"] = odds.apply(lambda x : f'{x["odds"]:.2f} ({x[0]:.2f}, {x[1]:.2f})', axis=1)
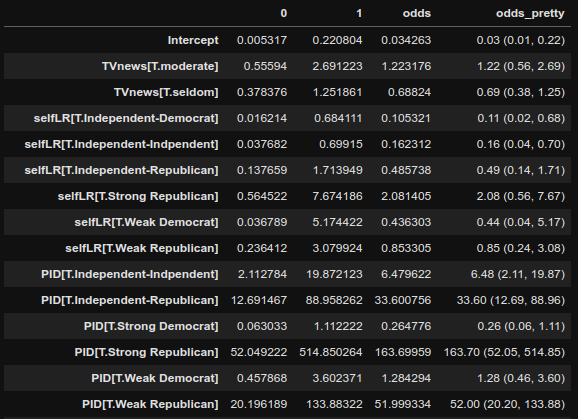
あとは,このDataFrameを .to_csv() などで出力してあげれば,コピーアンドペーストの手間を大葉に省ける.
その他の何か必要な値にアクセスしたい場合は,dir(res)でアクセス出来るattributeやmethodが表示されるので探索してみると解決するかもしれない.
以上.
----------雑感(`・∀・´)---------
Pythonでも論文で使えるレベルの数値の算出をかなり円滑に出来るようになってきている気がする.特にデータクリーニング時点でのpandasのmethod chainingと,statsmodelsのformulaのおかげでRと実装のしやすさで勝負出来るレベルに来ているのかなと.
因果推論に関しては,Directed Acyclic GraphsとTable 2 Fallacyに関して,以下のサイトで押さえとくべき.
・Learn about DAGs and DAGitty
また,統計モデリングの入門書は緑本.とりあえず重くないし読もう.


コメント